Introduction
Katonic - What It Is and Who It Is For
Welcome to your first steps into the exciting world of MLOps !
If you are a data scientist trying to get your models into production, or a data engineer trying to make your models scalable and reliable, Katonic provides tools to help. Katonic solves the problem of how to take machine learning from research to production.
Model Development Life Cycle
The MLOps lifecycle encompasses seven integrated and iterative processes, as shown in figure 1
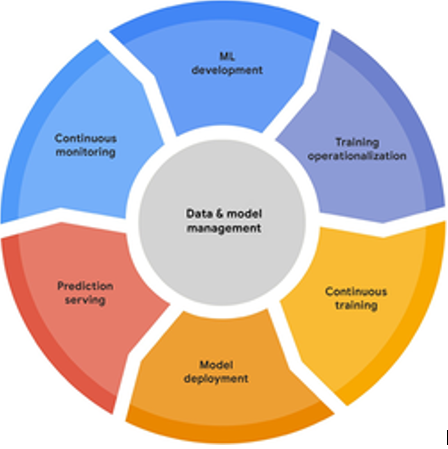
The processes are briefly described as follows:
ML development concerns experimenting and developing a robust and reproducible model training procedure (training pipeline code), which consists of multiple tasks from data preparation and transformation to model training and evaluation.
Training operationalization concerns about automating the process of packaging, testing, and deploying repeatable and reliable training pipelines.
Continuous training means repeatedly executing the training pipeline in response to new data or to code changes, or on a schedule, potentially with new training settings.
Model deployment concerns packaging, testing, and deploying a model to a serving environment for online experimentation and production serving.
Prediction serving is about serving the model that is deployed in production for inference.
Continuous monitoring is about monitoring the effectiveness and efficiency of a deployed model.
Data and model management is a central, cross-cutting function for governing ML artifacts to support audit, traceability, and compliance. Data and model management can also promote the shareability, reusability, and discoverability of ML assets.
Where Does Katonic Fit In?
Katonic is a collection of cloud-native tools for all of the stages of MDLC (data exploration, feature preparation, model training/tuning, model serving, model testing, and model versioning). Katonic provides a Unified UI and has tooling that allows these traditionally separate tools to work seamlessly together. An important part of this tooling is the pipeline system, which allows users to build integrated end-to-end pipelines that connect all components of their MDLC.
Katonic is for both data scientists and data engineers looking to build production-grade machine learning implementations. Katonic can be run either locally in your development environment or on a production cluster. Often pipelines will be developed locally and migrated once the pipelines are ready. Katonic provides a unified system—leveraging Kubernetes for containerization and scalability, for the portability and reusability of its pipelines.
Katonic MLOps Platform delivers the following AI/ML functionality
Spins up distributed, scalable, machine learning, and deep learning training environments in minutes rather than months — on-premises, public cloud, or in a hybrid model.
Leverages the power of containers to create complex machine learning and deep learning stacks that include distributed TensorFlow, Apache Spark, and Python ML and DL toolkits.
Enables a choice of programming languages and open-source tools to support even the most complex ML pipelines. For example, start with data pre-processing in Spark with Scala, followed by model development with TensorFlow on GPUs, and finally model deployment on CPUs with TensorFlow runtime.
Implements CI/CD processes for your ML projects with a model registry. Model registry stores models and versions created within Katonic ML Ops Platform.
Improves the reliability and reproducibility of machine learning projects a shared source control repository (Github & BitBucket).
Enables the deployment of models in production with secure, scalable, highly available endpoint deployment with out of the box auto-scaling, and load balancing.
Allows data scientists to focus on the core task of building ML models to improve business outcomes rather than managing infrastructure.
Enables Out-of-the-box application images to rapidly deploy containerized environments – sandbox, distributed training, or serving (inferencing) — with popular ML and DL tools, interfaces and languages. Such as Python, R-Studio, TensorFlow, Spark, and more.
Enables the creation of custom application images with any combination of tools, library packages, and frameworks to suit your needs.
Why Containerize?
The isolation provided by containers allows machine learning stages to be portable and reproducible. Containerized applications are isolated from the rest of your machine and have all their requirements included (from the operating system up). Containerization means no more conversations that include “It worked on my machine” or “Oh yeah, we forgot about just one, you need this extra package.”
Containers are built-in composable layers, allowing you to use another container as a base. For example, if you have a new natural language processing (NLP) library you want to use, you can add it on top of the existing container—you don’t have to start from scratch each time. The composability allows you to reuse a common base; for example, the R and Python containers we use both share a base Debian container.
Why Kubernetes?
Kubernetes is an open-source system for automating the deployment, scaling, and management of containerized applications. It allows our pipelines to be scalable without sacrificing portability, enabling us to avoid becoming locked into a specific cloud provider. In addition to being able to switch from a single machine to a distributed cluster, different stages of your machine learning pipeline can request different amounts or types of resources. For example, your data preparation step may benefit more from running on multiple machines, while your model training may benefit more from computing on top of GPUs or tensor processing units (TPUs). This flexibility is especially useful in cloud environments, where you can reduce your costs by using expensive resources only when required. Katonic provides a common interface over the tools you would likely use for your machine learning implementations. It also makes it easier to configure your implementations to use hardware accelerators like TPUs without changing your code.
Katonic’s Design and Core Components
In the machine learning landscape, there exists a diverse collection of libraries, tool sets, and frameworks. Katonic does not seek to reinvent the wheel or provide a “one size fits all” solution, instead, it allows machine learning practitioners to compose and customize their own stacks based on specific needs. It is designed to simplify the process of building and deploying machine learning systems at scale. This allows data scientists to focus their energies on model development instead of infrastructure.
Katonic seeks to tackle the problem of simplifying machine learning through three features: composability, portability, and scalability.
- Composability
The core components of Katonic come from data science tools that are already familiar to machine learning practitioners. They can be used independently to facilitate specific stages of machine learning, or composed together to form end-to-end pipelines.
- Portability
By having a container-based design and taking advantage of Kubernetes and its cloud-native architecture, Katonc does not require you to anchor to any particular development environment. You can experiment and prototype on your laptop, and deploy to production effortlessly.
- Scalability By using Kubernetes, Katonic can dynamically scale according to the demand on your cluster, by changing the number and size of the underlying containers and machines.
These features are critical for different parts of MDLC. Scalability is important as your dataset grows. Portability is important to avoid vendor lock-in. Composability gives you the freedom to mix and match the best tools for the job.
Let’s take a quick look at some of Katonic’s components and how they support these features.
Data Exploration with Notebooks
MDLC always begins with data exploration—plotting, segmenting, and manipulating your data to understand where possible insight might exist. One powerful tool that provides the tools and environment for such data exploration is Jupyter. Jupyter is an open-source web application that allows users to create and share data, code snippets, and experiments. Jupyter is popular among machine learning practitioners due to its simplicity and portability.
In Katonic, you can spin up instances of Jupyter that directly interact with your cluster and its other components. For example, you can write snippets of TensorFlow distributed training code on your laptop, and bring up a training cluster with just a few clicks.
Connectors
Katonc provides over 75 Connectors to help you connect data from any cloud, on-premises, or proprietary system. This will make disparate data assets accessible and available for model development.
Data/Feature Preparation
Machine learning algorithms require good data to be effective, and often special tools are needed to effectively extract, transform, and load data. One typically filters, normalizes, and prepares one’s input data in order to extract insightful features from otherwise unstructured, noisy data. Katonic supports a few different tools for this:
Apache Spark (one of the most popular big data tools)
TensorFlow Transform (integrated with TensorFlow Serving for easier inference)
These distinct data preparation components can handle a variety of formats and data sizes and are designed to play nicely with your data exploration environment.
Training
Once your features are prepped, you are ready to build and train your model. Katonic supports a variety of distributed training frameworks like:
TensorFlow
PyTorch
Apache MXNet
XGBoost
Chainer
Caffe2
Message passing interface (MPI)
Hyperparameter Tuning
How do you optimize your model architecture and training? In machine learning, hyperparameters are variables that govern the training process. For example, what should the model’s learning rate be? How many hidden layers and neurons should be in the neural network? These parameters are not part of the training data, but they can have a significant effect on the performance of the training models.
With Katonic, users can begin with a training model that they are unsure about, define the hyperparameter search space, and Katonic will take care of the rest. Spin up training jobs using different hyperparameters, collect the metrics, and save the results so that their performance can be compared.
Model Validation
Before you put your model into production, it’s important to know how it’s likely to perform. The same tool used for hyperparameter tuning can perform cross-validation for model evaluation. When you’re updating existing models, techniques like A/B testing and multi-armed bandit can be used in model inference to validate your model online.
Model Registry
The model registry capability lets you govern the lifecycle of the ML models in a central repository. This ensures the quality of the production models and enables model discovery. Katonic provides model lineage, model versioning, stage transitions (for example from staging to production or archiving), and annotations.
A model registry is a place where trained machine learning (ML) models can be stored. A model registry holds information (metadata) about the data and training jobs used to generate the model in addition to the models themselves. To recreate a trained model from scratch, it's critical to keep track of these required inputs. In this sense, a model registry functions similarly to traditional software's version control systems (e.g., Git, SVN) and artifact repositories (e.g., Artifactory, PyPI).
Inference/Prediction
After training your model, the next step is to serve the model in your cluster so it can handle prediction requests. Katonic makes it easy for data scientists to deploy machine learning models in production environments at scale using our in-house model serving system.
Serving many types of models on Katonic's platform is fairly straightforward. In most situations, there is no need to build or customize a container yourself—simply point Katonic to where your model is stored, and a server will be ready to service requests.
Once the model is served, it needs to be monitored for performance and possibly updated. This monitoring and updating is possible via the cloud-native design of Katonic and will be further expanded upon later.
Pipelines
Now that we have completed all aspects of MDLC, we wish to enable the reusability and governance of these experiments. To do this, Katonic treats MDLC as a machine learning pipeline and implements it as a graph, where each node is a stage in a workflow. Kubeflow Pipelines is a component that allows users to compose reusable workflows at ease. Its features include:
An orchestration engine for multistep workflows
An SDK to interact with pipeline components
A user interface that allows users to visualize and track experiments, and to share results with collaborators
Component Overview
As you can see, Katonic has built-in components for all parts of MDLC: data preparation, feature preparation, model training, data exploration, hyperparameter tuning, and model inference, as well as pipelines, to coordinate everything. However, you are not limited to just the components shipped as part of Katonic. The Katonic team can help you build on top of the components or even replace them.