NLP Model Monitoring
For NLP model monitoring dashboard
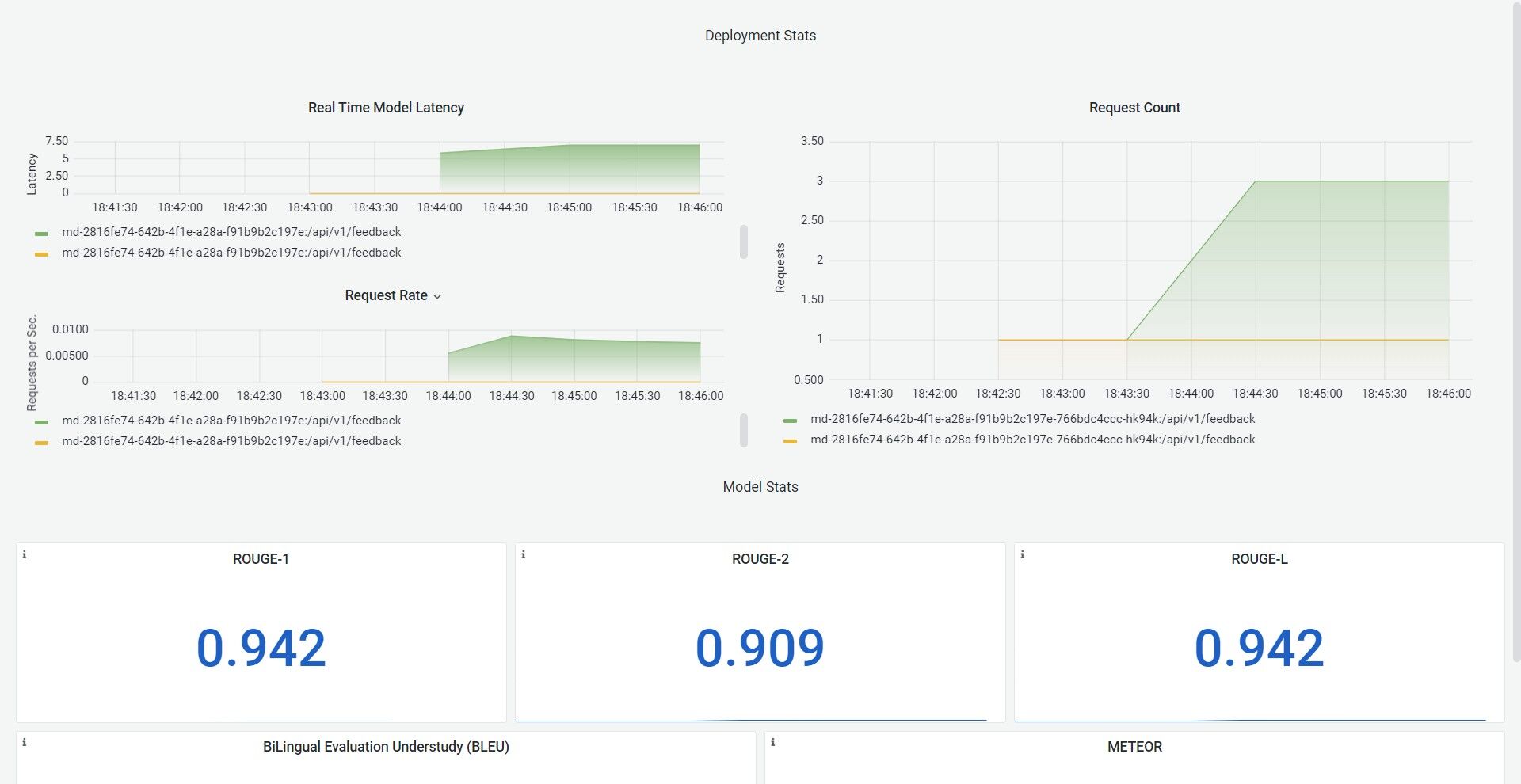
BLEU Score: BLEU (Bilingual Evaluation Understudy) score is a commonly used metric for evaluating the quality of machine translation output. It was originally designed for evaluating translation from one language to another, but it has since been adapted for other natural language processing tasks, including summarization and text generation.
Rouge: ROUGE (Recall-Oriented Understudy for Gisting Evaluation) score is a metric that can be used to evaluate the quality of summarization, translation, and text generation output. While the exact implementation of ROUGE can vary depending on the specific task, the basic idea is to measure the overlap of n-grams (contiguous sequences of n words) between the generated text and one or more reference texts.
Meteor: METEOR (Metric for Evaluation of Translation with Explicit Ordering) score is a metric that can be used to evaluate the quality of summarization, translation, and text generation output.
For a prediction input:
{
"predicted_label":[
"Meditation is an ancient practice that has gained popularity for its positive effects on mental health. Studies have shown that it can reduce anxiety and depression symptoms, improve attention and concentration, and increase happiness and well-being."],
"true_label" :[
"Meditation is an ancient practice that has gained popularity for its positive effects on mental health. Studies have shown that it can reduce anxiety and depression symptoms, improve attention and concentration, and increase happiness and well-being. It also lowers cortisol levels, which can improve physical health.",
"Meditation is an ancient practice that has gained popularity for its positive effects on mental health. Studies have shown that it can reduce anxiety and depression symptoms, improve attention and concentration, and increase happiness and well-being."
]
}
# More precisely, for a single prediction, 1 of more reference values to compare to.