Audio Classification Model Monitoring
Audio classification is the process of categorizing audio recordings based on their content. It is a popular application of machine learning that involves training a model to recognize and classify different types of sounds, such as music, speech, animal sounds, or environmental noise. When it comes to model monitoring, audio classification can be useful in several ways. For instance, if you have a production system that uses an audio classification model to classify incoming audio streams, you may want to monitor the model's performance to ensure that it is working correctly and providing accurate results.
For Audio Classification monitoring dashboard
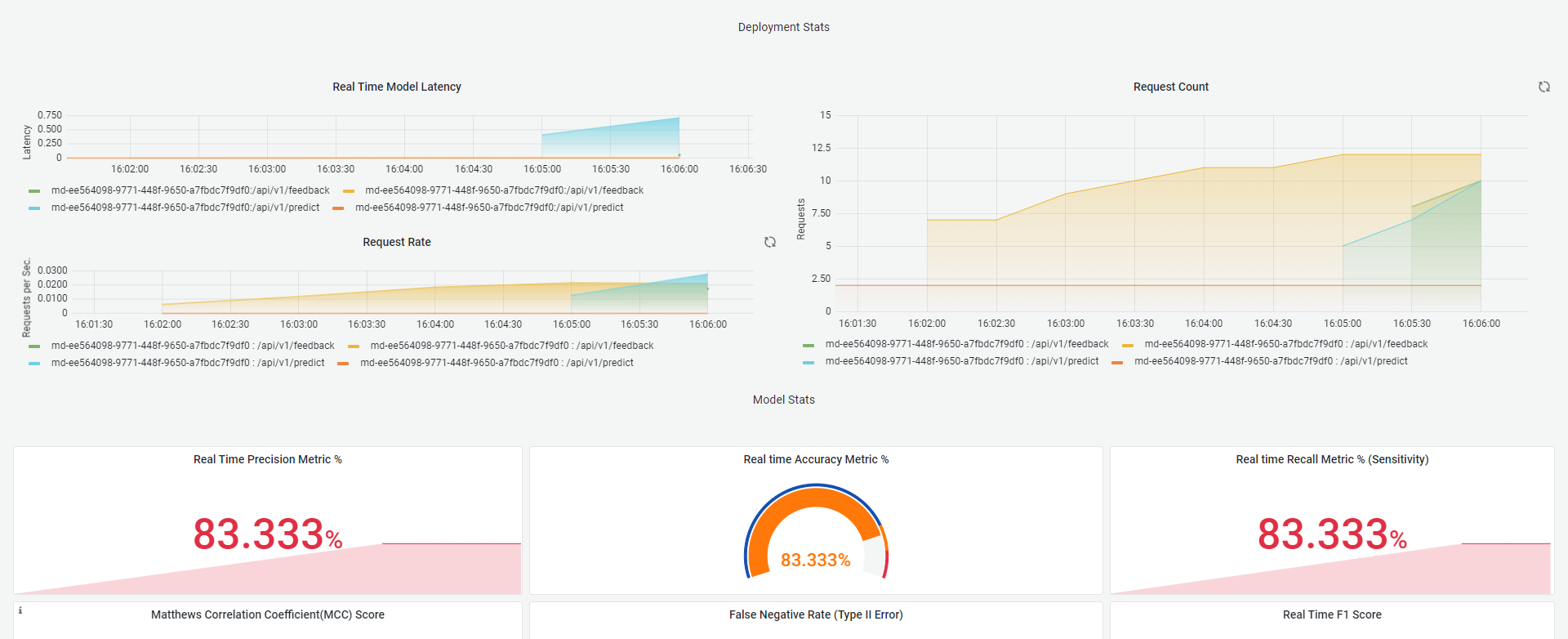
Metrics for monitoring Audio Classification models
1. Accuracy
One of the most important metrics for monitoring an audio classification model is its accuracy. You can measure accuracy by comparing the model's predictions to the ground truth labels for a set of audio samples. You can track accuracy over time to identify any changes in the model's performance
2. Precision
In the context of audio classification, precision can be calculated by dividing the number of correctly classified instances of a particular class by the total number of instances predicted as that class. For example, if a model predicts that a particular audio clip is a dog bark, and it is actually a dog bark, this would be considered a true positive for the dog bark class. If the model predicted that another audio clip is a dog bark, but it is actually a car honk, this would be a false positive for the dog bark class.
The precision for the dog bark class would then be calculated by dividing the number of true positives for the dog bark class by the total number of instances predicted as the dog bark class (both true positives and false positives). A high precision score indicates that the model is accurately identifying instances of the relevant class and is less likely to misclassify other classes.
3. Recall
In the context of audio classification, recall can be calculated by dividing the number of correctly classified instances of a particular class by the total number of instances that actually belong to that class. For example, if there are 100 instances of dog barks in a dataset, and a model correctly identifies 90 of them as dog barks, this would be considered a true positive for the dog bark class. If the model misclassifies 10 dog barks as some other class, this would be a false negative for the dog bark class.
The recall for the dog bark class would then be calculated by dividing the number of true positives for the dog bark class by the total number of instances that actually belong to the dog bark class (both true positives and false negatives). A high recall score indicates that the model is able to detect most instances of the relevant class, but may also have a higher likelihood of misclassifying instances of other classes as that class.
4. F1 score
The F1 score is a commonly used performance metric in audio classification and other classification tasks. It is a measure of the model's accuracy that takes into account both precision and recall. The F1 score is the harmonic mean of precision and recall, and it ranges from 0 to 1, with a higher score indicating better performance.
The F1 score balances precision and recall, meaning it is a useful metric for situations where false positives and false negatives are equally important. For example, in a security application where the detection of gunshots is critical, both false positives (misclassifying a non-gunshot sound as a gunshot) and false negatives (missing a real gunshot) could have severe consequences. In this case, the F1 score would be a useful metric to evaluate the model's performance.
5. Matthews Correlation Coefficient (MCC)
The Matthews Correlation Coefficient (MCC) is another performance metric commonly used for evaluating the accuracy of an audio classification model. The MCC takes into account true positives, true negatives, false positives, and false negatives and provides a balanced measure of the model's performance.
A high MCC value indicates that the model is accurately predicting the class labels and is less likely to misclassify instances. The MCC is particularly useful in situations where the classes are imbalanced, meaning that there are significantly more instances of one class than another. In such cases, accuracy can be a misleading metric as a model that always predicts the majority class will have a high accuracy, but may perform poorly on the minority class. The MCC provides a more balanced measure of the model's performance that takes into account all classes.
6. F2 Score
The F2 score is a variation of the F1 score that places more emphasis on recall than precision. It is particularly useful in situations where the cost of false negatives is higher than the cost of false positives.
The F2 score is particularly useful in applications where the cost of missing instances of a particular class is high, such as in medical diagnosis or in identifying critical sounds in industrial settings.
7. False Negative Rate (FNR)
False Negative Rate (FNR) is a performance metric that measures the proportion of actual positive instances that are incorrectly classified as negative by the audio classification model. In other words, it is the ratio of the number of false negatives to the total number of actual positive instances.
In the context of audio classification, a high FNR indicates that the model is not correctly identifying instances of the relevant class, leading to a higher number of false negatives. This means that the model is missing a significant number of relevant sounds, which could have important implications depending on the application. For example, in a security application, a high FNR could mean that gunshots are being missed by the model, which could lead to serious consequences. Therefore, minimizing FNR is an important objective when evaluating and optimizing audio classification models, especially in applications where it is crucial to identify all relevant sounds.
8. False Positive Rate (FPR)
False Positive Rate (FPR) is a performance metric that measures the proportion of negative instances that are incorrectly classified as positive by the audio classification model. In other words, it is the ratio of the number of false positives to the total number of actual negative instances.
In the context of audio classification, a high FPR indicates that the model is incorrectly identifying instances of the relevant class, leading to a higher number of false positives. This means that the model is identifying sounds as belonging to the relevant class, even though they do not belong to that class. This can lead to unnecessary actions being taken, depending on the application. For example, in a security application, a high FPR could mean that non-gunshot sounds are being classified as gunshots, leading to unnecessary alerts or responses.
Therefore, minimizing FPR is an important objective when evaluating and optimizing audio classification models, especially in applications where false positives can have significant consequences.
9. True Negative Rate (TNR)
True Negative Rate (TNR), also known as specificity, is a performance metric that measures the proportion of negative instances that are correctly identified as negative by the audio classification model. In other words, it is the ratio of the number of true negatives to the total number of actual negative instances. In the context of audio classification, a high TNR indicates that the model is correctly identifying instances that do not belong to the relevant class, leading to a lower number of false positives. This means that the model is able to correctly distinguish between sounds that belong to the relevant class and those that do not, which is important in applications where false positives can have significant consequences.
TNR is also useful in situations where the classes are imbalanced, meaning that one class has significantly more instances than the other. In such cases, a high TNR indicates that the model is performing well on the negative class, which can provide a more balanced measure of the model's performance.
10. Negative Predictive Value (NPV)
Negative Predictive Value (NPV) is a performance metric that measures the proportion of negative predictions that are actually negative in the audio classification model. In other words, it is the ratio of the number of true negatives to the total number of negative predictions made by the model.
In the context of audio classification, a high NPV indicates that the model is accurately predicting negative instances, leading to a lower number of false negatives. This means that the model is able to correctly distinguish between sounds that belong to the relevant class and those that do not, which is important in applications where false negatives can have significant consequences.
11. False Discovery Rate (FDR)
False Discovery Rate (FDR) is a performance metric that measures the proportion of positive predictions that are actually negative in the audio classification model. In other words, it is the ratio of the number of false positives to the total number of positive predictions made by the model.
In the context of audio classification, a high FDR indicates that the model is incorrectly predicting positive instances, leading to a higher number of false positives. This means that the model is identifying sounds as belonging to the relevant class, even though they do not belong to that class. This can lead to unnecessary actions being taken, depending on the application. For example, in a security application, a high FDR could mean that non-gunshot sounds are being classified as gunshots, leading to unnecessary alerts or responses.
12. Equal Error Rate (EER)
The EER is particularly useful in applications where the cost of false positive and false negative errors is approximately equal. It provides a single measure of the model's performance that allows for comparison with other systems or benchmarks.
However, it should be noted that EER is not always the most appropriate metric for evaluating audio classification models, especially if the classes are imbalanced or if the cost of false positive and false negative errors is not equal. In such cases, other performance metrics such as F1-score, MCC, or weighted accuracy may be more suitable.
For Feedback input:
Emotions available = { "01": "neutral", "02": "calm", "03": "happy", "04": "sad", "05": "angry", "06": "fearful", "07": "disgust", "08": "surprised" }
{
"predicted_label": ['06', '04', '01', '06', '07','04'],
"true_label": ['06', '03', '01', '06', '07','02']
}
# Both the input has to be a 1d array or list.