Cost Requests
Request Specific Cost Analysis:
Note: Administrator privileges are necessary to access the cost management modules on the platform.
The Request-specific cost analysis feature provides a versatile tool for in-depth examination of costs across different dimensions, including project, user, and model perspectives. This functionality allows users to conduct detailed project-based cost analyses, gaining insights into resource consumption specific to each project. Additionally, it facilitates user-based cost analysis, enabling the assessment of individual user contributions to overall expenses. Furthermore, the feature extends its utility to model-based analysis, allowing users to scrutinize the cost implications associated with each deployed model.
These requests are generated whenever you make a request from various functionalities such as chat, extract, summarize, generate, classify, embeddings, tuning-studio, and multimodal. With this comprehensive approach, stakeholders can make informed decisions regarding resource allocation, budgeting, and optimization strategies.
To access the Request specific cost analysis dashboard, follow these steps:
Login to Katonic Generative AI Platform:
Log in to your Katonic Generative AI platform account using your credentials.
Navigate to the Admin Section:
Once logged in, click on the 'Admin' section in the platform's interface.
Select Cost Insights Board:
Within the Admin section, locate and select the 'Requests' board.
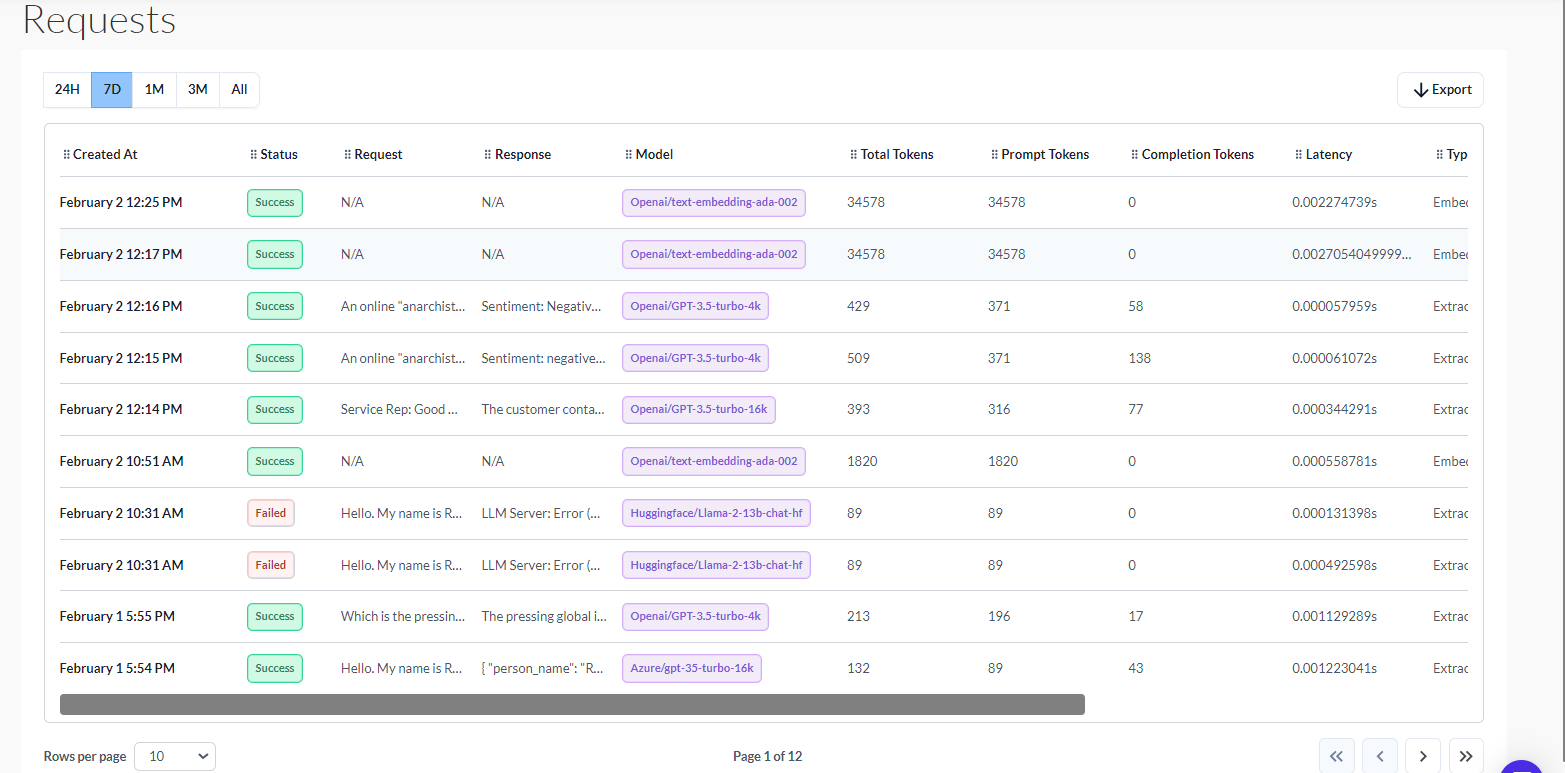
Request specific Dashboard:
The following details will be available in the request specific cost dashboard.
Flexible Time Analysis: Effortlessly analyze requests over various time periods by applying intuitive filters.
Comprehensive Request Logging: Every request made across the platform is meticulously logged, providing a detailed overview of each interaction.
Each logged request includes the following details:
Created at Timestamp: Records the time when the request was created.
Status of the Request: Indicates whether the request was successful or encountered issues.
Request: Represents the input provided for the LLM.
Response: Displays the output generated by the model.
Model: Specifies the name of the LLM model used for the request.
Total Tokens: Reflects the total number of tokens utilized throughout the entire request.
Prompt Tokens: Identifies the number of input tokens used for the request.
Completion Tokens: Quantifies the tokens employed for the output generated by the model.
Latency: Measures the response time for the model to generate the output.
Type: Specifies the project type in which the request occurred (e.g., Chatbot, Extraction, Summarize, Generate, or Multimodal).
Username: Records the name of the user who initiated the request.
Cost: Indicates the total cost incurred for processing the request.