From Notebook to Kubeflow Pipeline using Katonic Studio
1. Get Started
Jupyter Notebook is a very popular tool that data scientists use every day to write their ML code, experiments, and visualize the results. However, when it comes to converting a Notebook to a Pipeline, data scientists struggle a lot. It is a very challenging, time-consuming task, and most of the time it needs the cooperation of several different subject-matter experts: Data Scientist, Machine Learning Engineer, Data Engineer.
A typical machine/deep learning pipeline begins as a series of preprocessing steps followed by experimentation/optimization and finally deployment. Each of these steps represents a challenge in the model development lifecycle. Katonic Studio provides a Pipeline Visual Editor for building AI pipelines from notebooks, Python scripts and R scripts, simplifying the conversion of multiple notebooks or scripts files into batch jobs or workflows.
This tutorial will guide you to use the Katonic Studio to assemble pipelines from Python notebooks or scripts without the need for any coding.
1.1 Sign In
Click here to open the login page to try the Katonic platform.
Enter Email and Password and click on the “Sign In” button to sign in to the Katonic platform.
1.2 Orient yourself to the Katonic platform
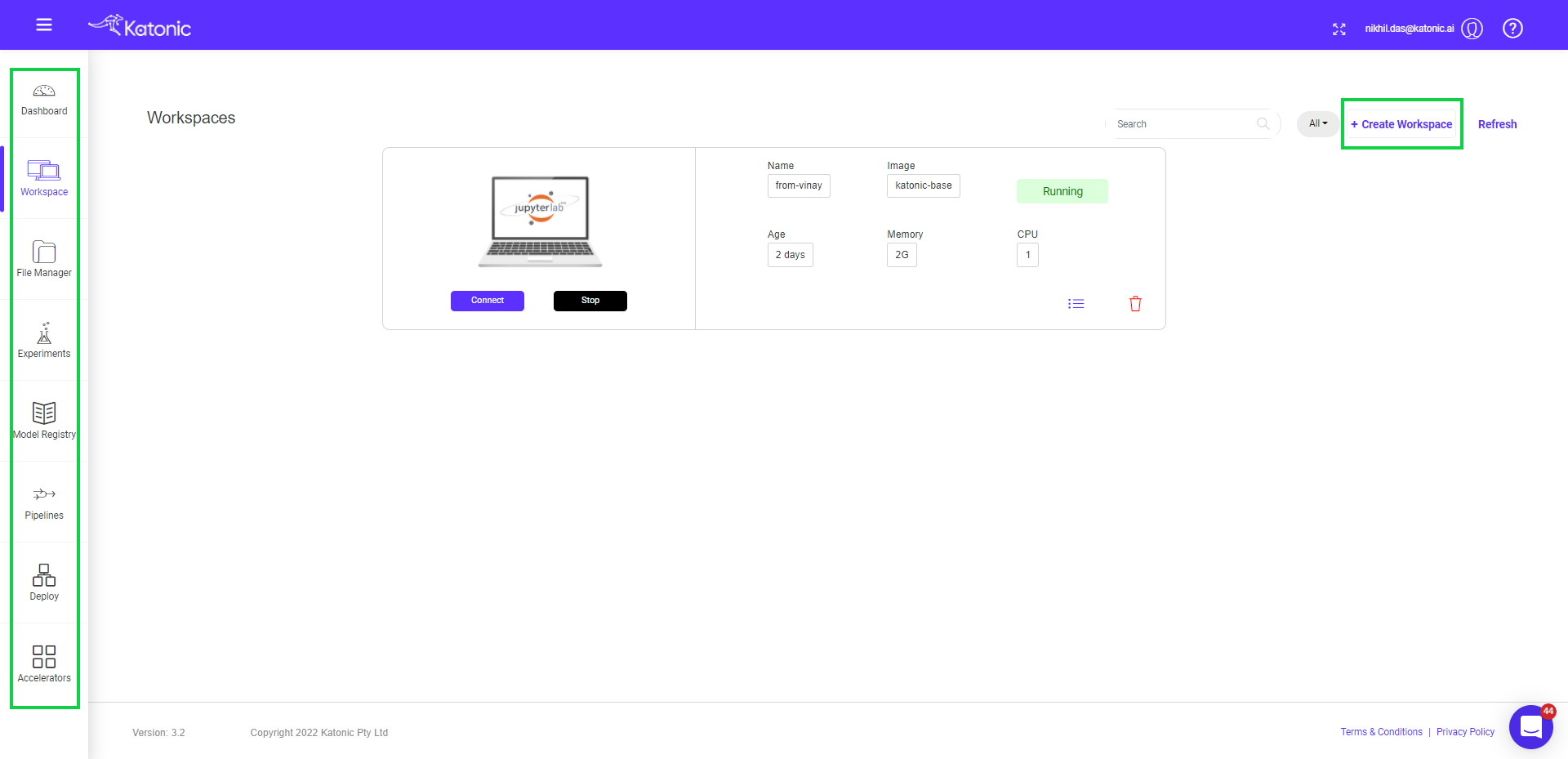
When you first log in, you will find yourself in the Dashboard section of Katonic. You can use the left sidebar to navigate to other sections of Katonic Platform.
To view the platform in full screen click on the “full-screen mode“ on the top right of the page.
If you click on the user icon on top of the right, you can find the option of “cluster monitoring”. Where you can see the performance of the cluster where the platform is installed.
If you would like to search the Katonic documentation for help, click on the “?” icon on the top right of the page.
To send a question to a member of the Katonic support staff, use the Support button on the bottom right of the page.
1.3 Create a Notebook
In the left sidebar, click on
Click on ‘Create Workspace’ in the top right side of the page
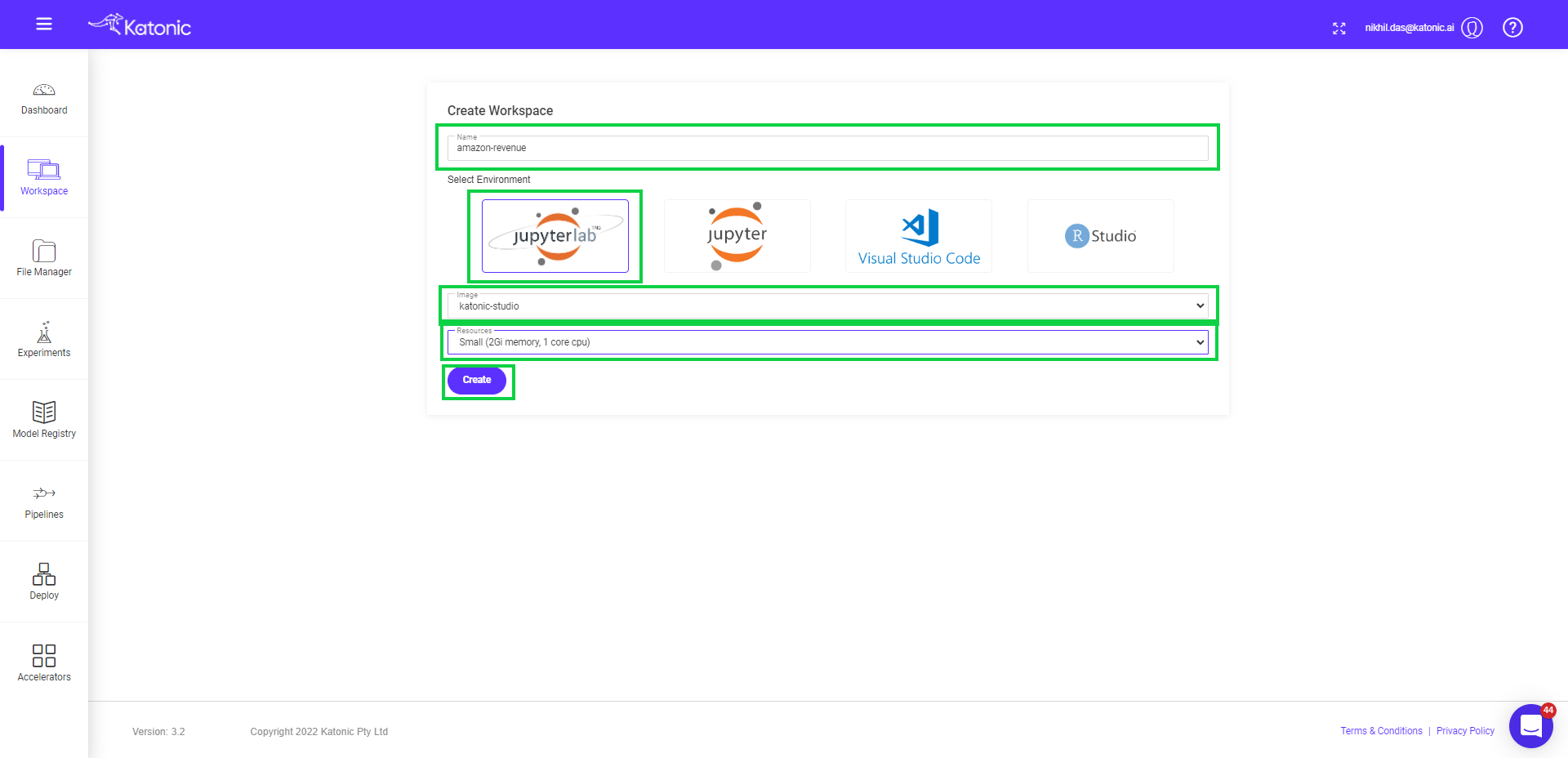
Give your Notebook an informative name (like amazon-revenue).
Note : Notebook name should contain only lowercase(a-z), numbers(0-9) and hyphen(-).
Select Environment as JupyterLab.
Select Image as Katonic Studio (Katonic-base is the default image. you can choose any or can also give any custom image) If you want to add any custom image click here for documentation.
Select the Number of CPUs and the memory you want to allocate to Notebook.
1.4 Start Notebook
- Once you create a workspace you could see it will be in 'processing' state.
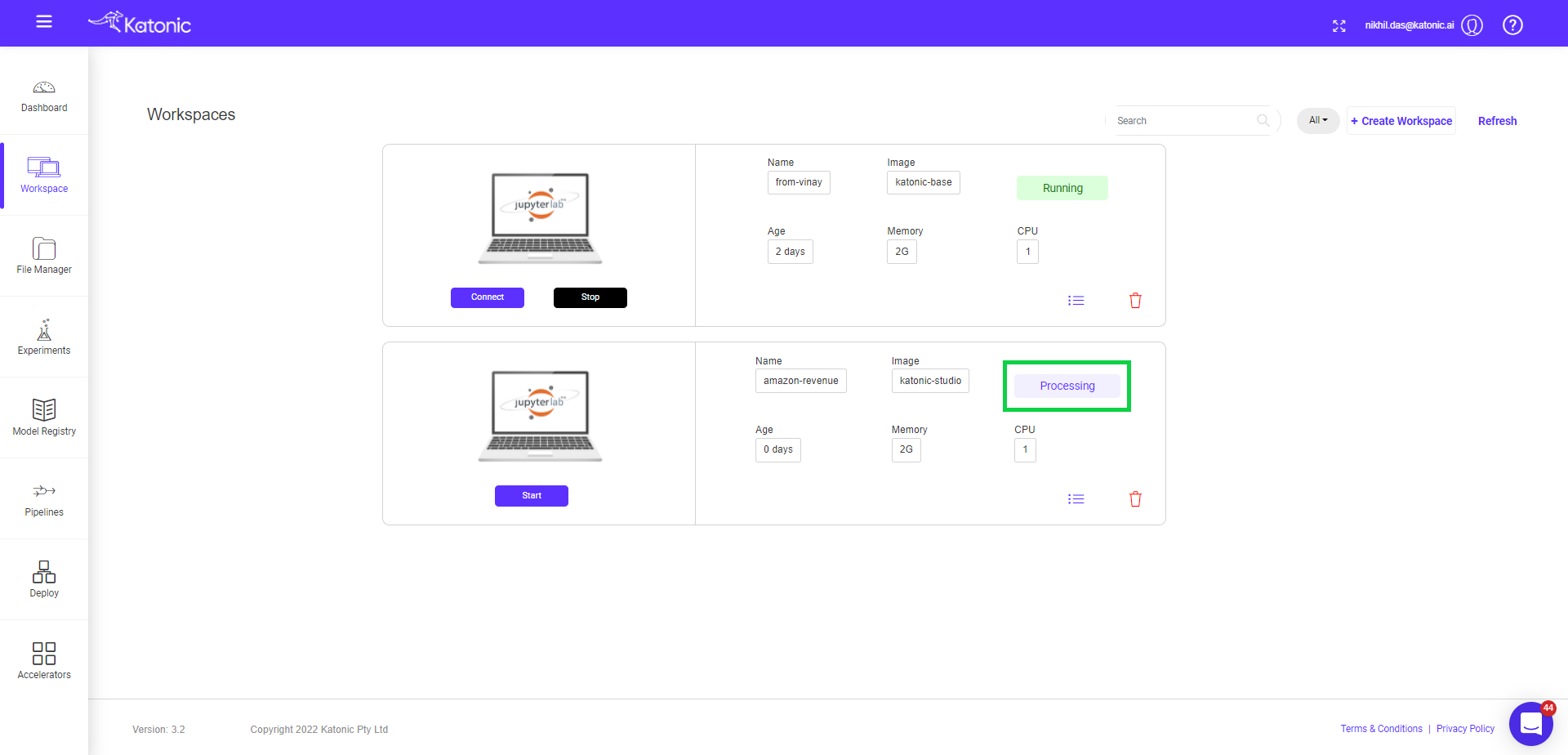
- Once the notebook has started it will show the connect button with which you can connect to the notebook server.
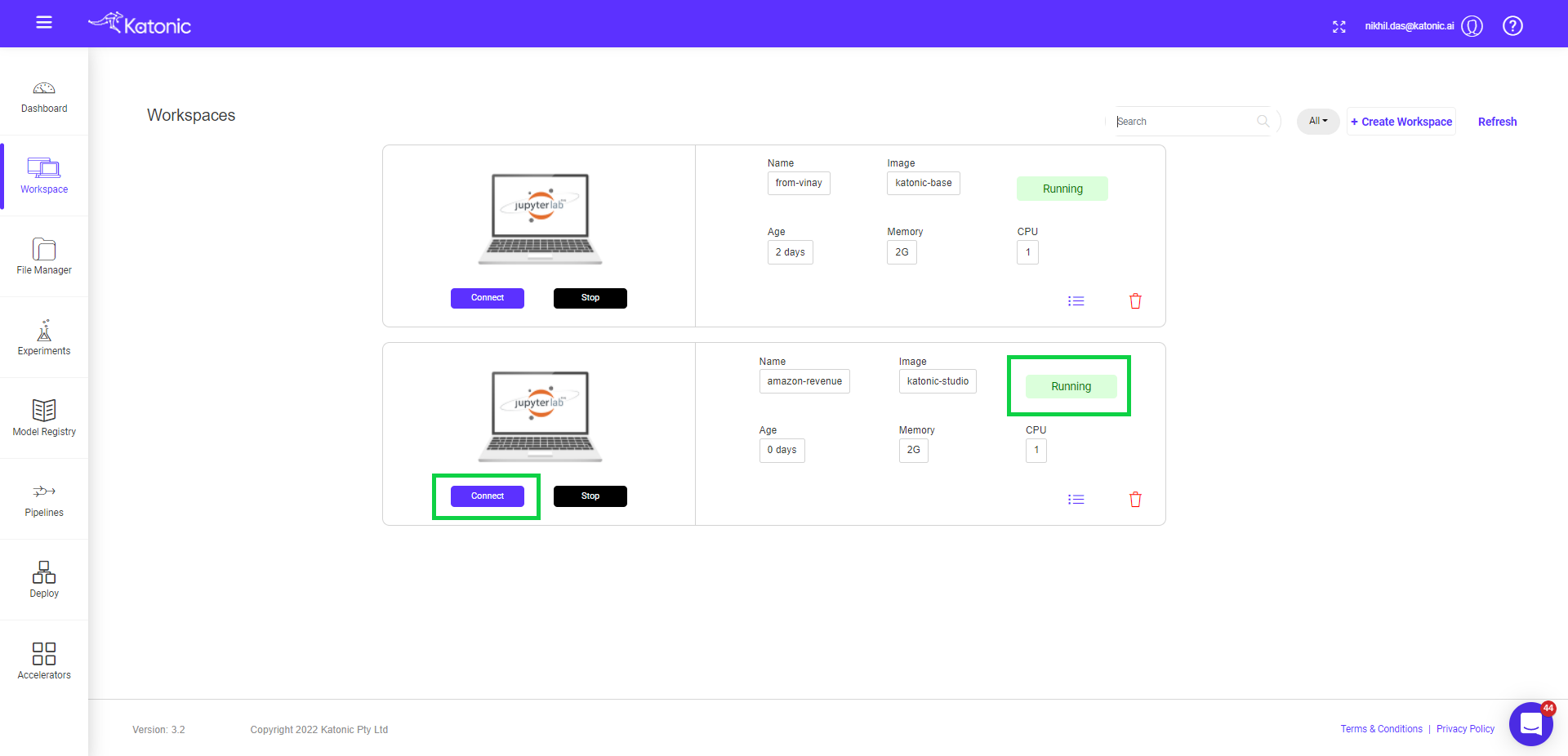
When you connect a notebook, a new session is created on a machine and your browser is automatically redirected to the notebook UI.
Once your notebook is up and running, you will see a fresh Jupyter interface. If you are new to Jupyter, you might find the Jupyter and Jupyterlab documentation helpful.
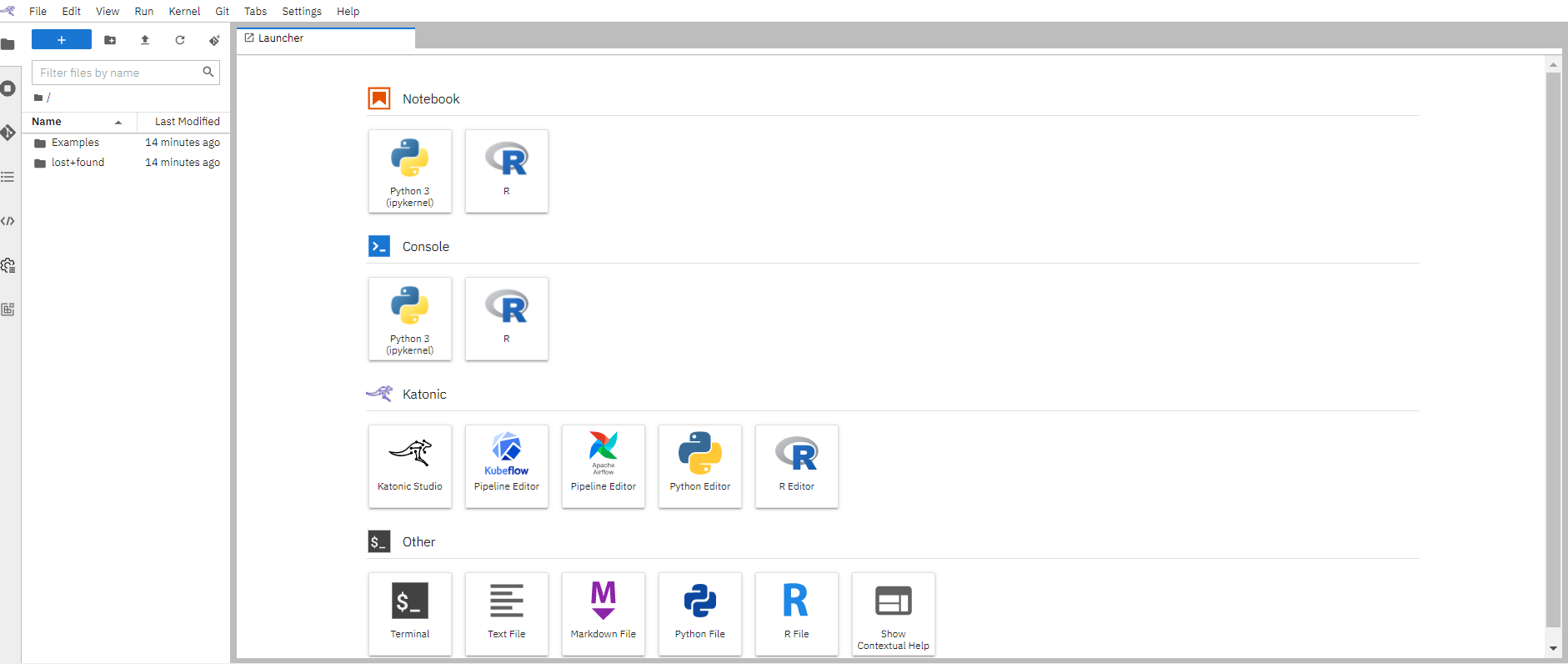
1.5 Configure Kubeflow Runtime
Runtime configuration can be listed, added, updated, duplicated and Removed in Runtime Panel.
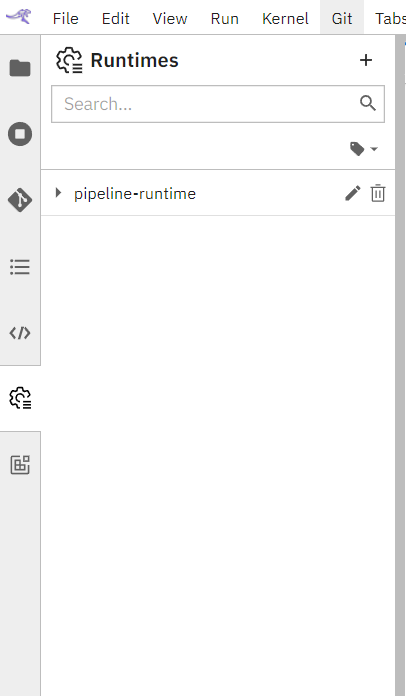
1.5.1 Accessing the panel
Click on Runtime panel from the Jupyterlab sidebar.
Click on the ‘+’ button on the top right.
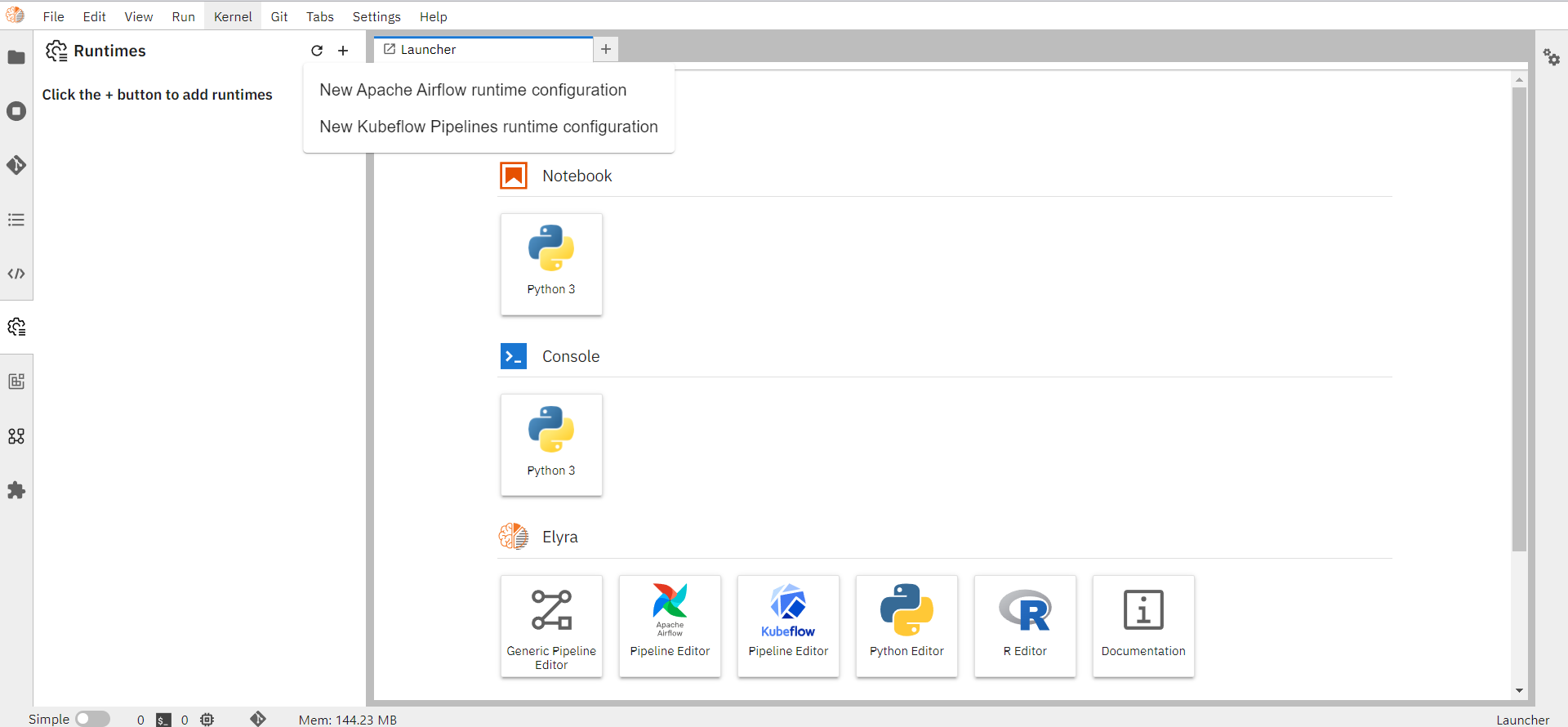
Select "New Kubeflow Pipelines runtime configuration".
Fill in all the details on the page.
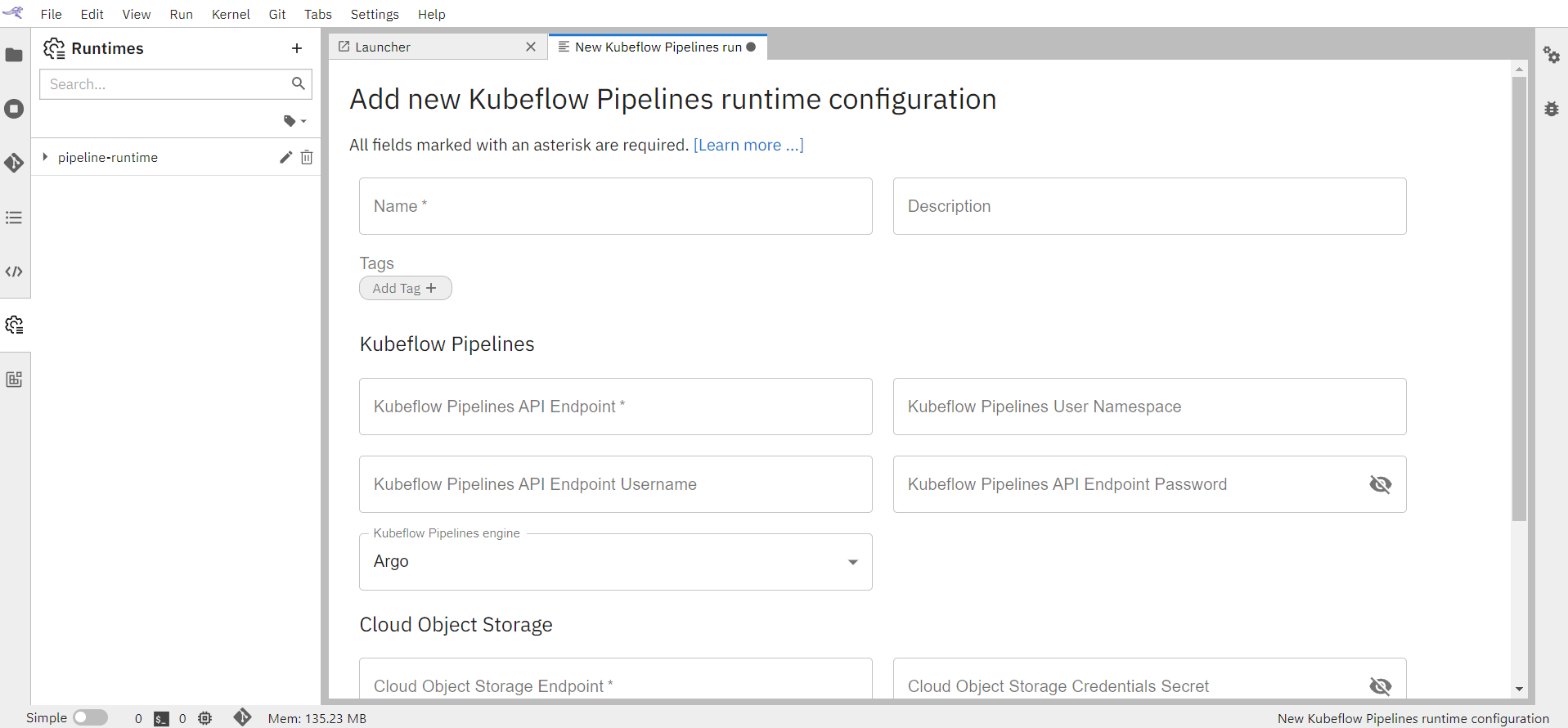
Provide a runtime configuration display name, an optional description, and tag the configuration to make it more easily discoverable.
Fill in the Cloud Object Storage.Refer to the section Cloud Object storage.
Click on SAVE & CLOSE with the given configurations.
Save the runtime configuration. The new entry is displayed in the list.
1.5.2 Cloud Object storage
Go to the File Manager from the left panel.Click on the Access token ,generate access token and secret keys by clicking Create Access Token.
Cloud Object Storage bucket name
Name of the bucket you want to store pipeline artifacts in. Buckets can be shared-storage or your private bucket name.
Cloud Object Storage username
Username used to connect to the cloud Object Storage, credentials are required for the selected authentication type USER_CREDENTIALS and KUBERNETES_SECRET.
Give your generated access token as username.Cloud Object Storage password
Password used to connect to the cloud Object Storage, credentials are required for the selected authentication type USER_CREDENTIALS and KUBERNETES_SECRET.
Give your generated secret key as password.
1.6 Configure Runtime Image
In this section, we can use the existing docker images available or create a new custom image or add an already created image from your docker hub for easy access.
Click on the “Runtime Images” Icon in the left bar
Click on the “+” button on the top right
Fill in all the details on the page
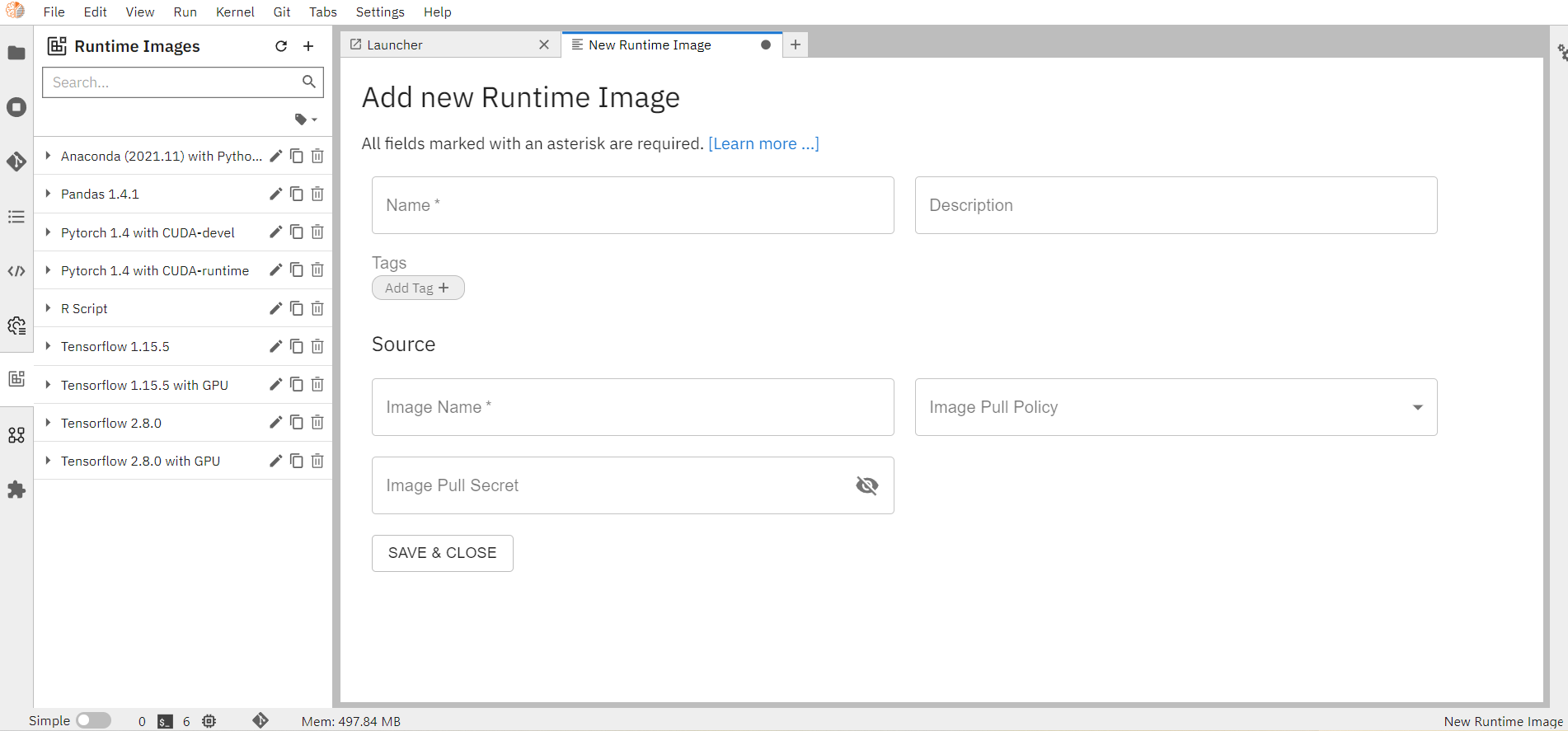
Name: User-friendly name that will appear under Runtime images list
Description(Optional) of the image. Small description defining your image
Image Name: Name of the image that you need from the docker hub.
Image Pull Policy: Select an option from the dropdown.
Click on “SAVE & CLOSE” to save the image.
A list of additional images can be seen in the left panel
1.7 Get your Files and Data
Some of the examples will already come with the workspace you set up. You can directly use those for your experimentation purpose or clone other examples from Github.
Files and Data can be created in the same environment or can be cloned from GitHub. In this section, we will be showing you how can you clone data and files from our open-source examples available on GitHub.
Click here for Katonic use cases repository
Click on the “Git” icon on the left bar
Click on the “Clone a Repository” button available in the left panel. This will open up a window.
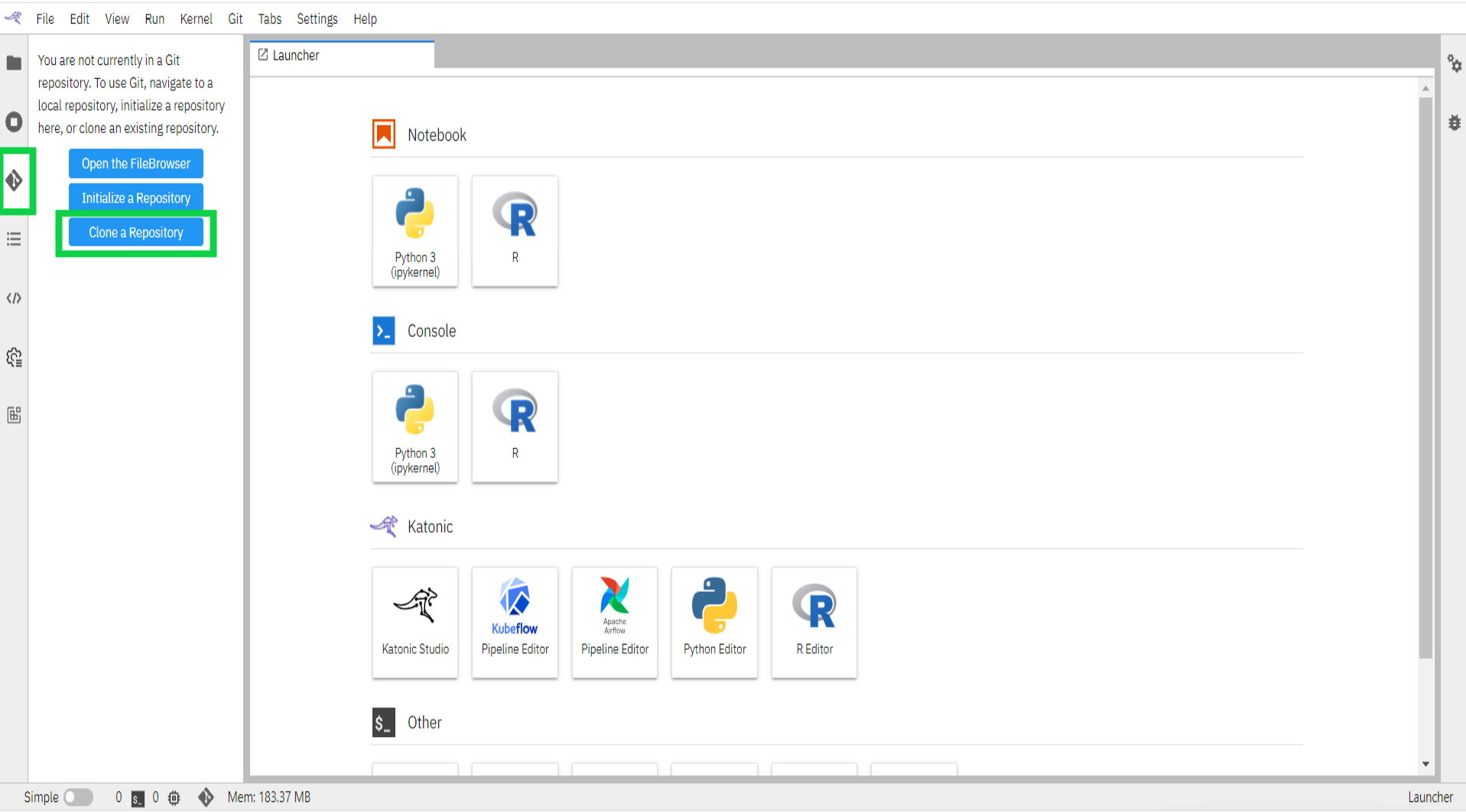
- Enter the Clone URI Link that is available in GitHub Repository.
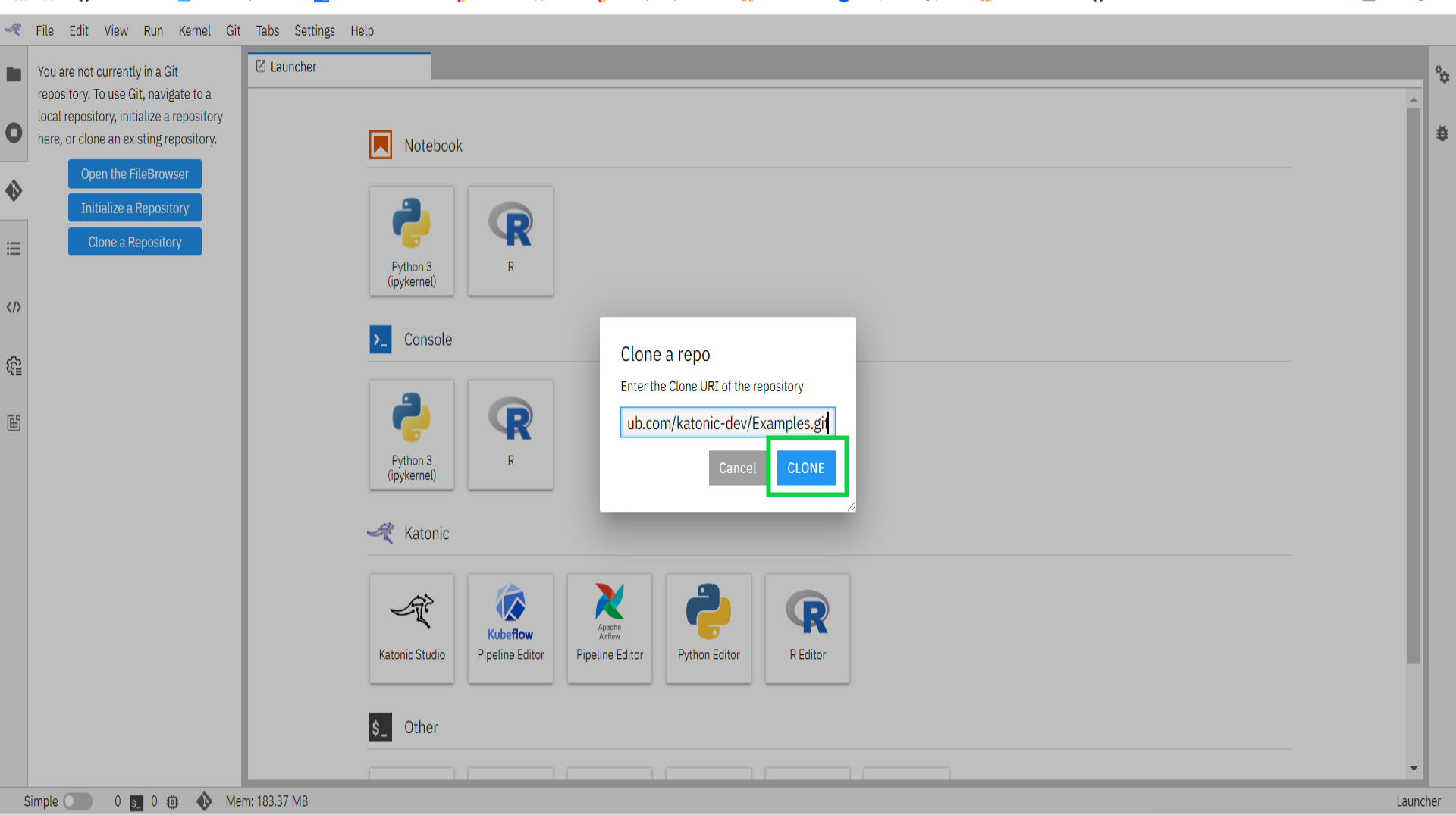
Click on the “clone” button.
This process will clone the whole repo into the workspace.
Click on “File Manager” in the left bar.
Go to location “/Examples/amazon_revenue_forcasting/”.
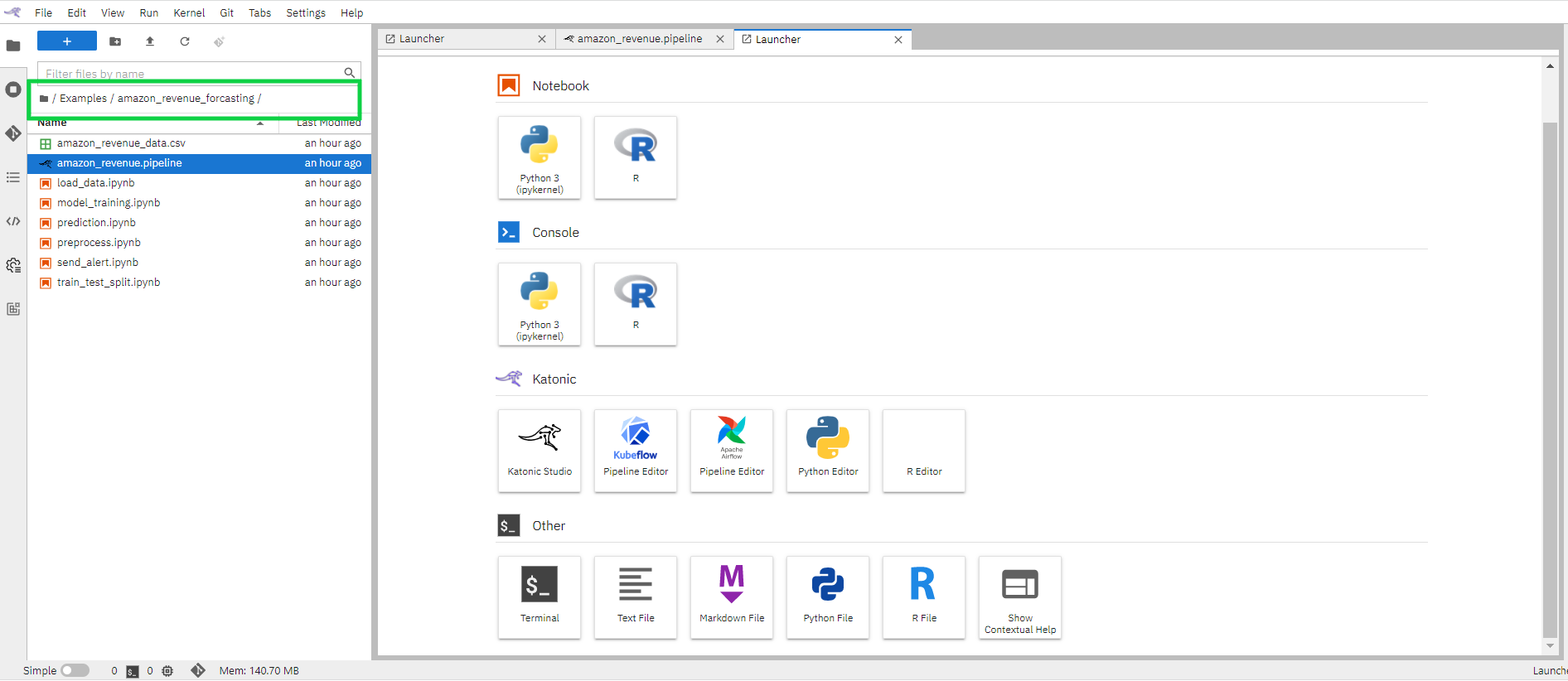
1.8 Creating pipeline
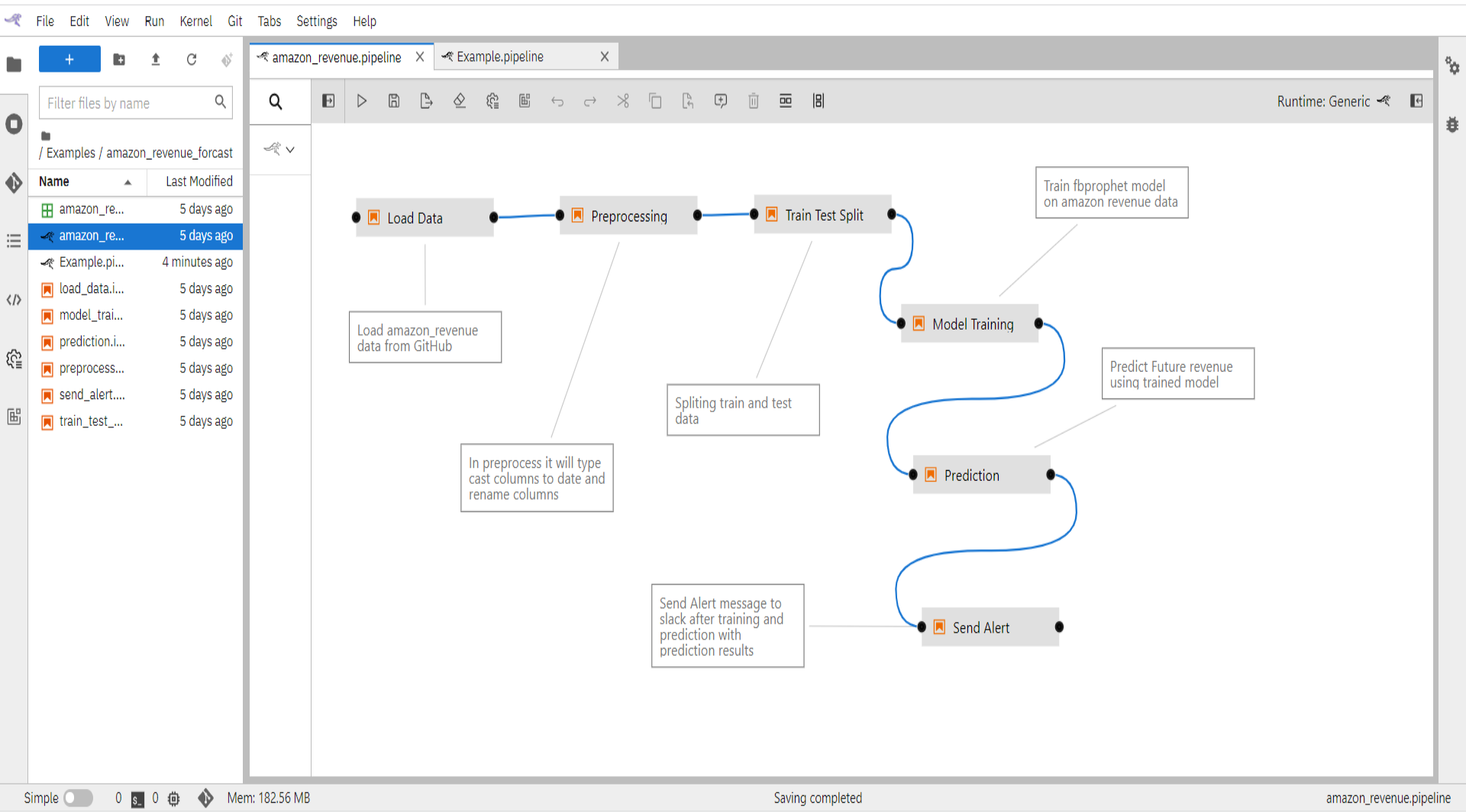
A pipeline comprises one or more nodes that are (in many cases) connected with each other to define execution dependencies. Each node is implemented by a component and typically performs only a single task, such as loading data, processing data, training a model, predicting, or sending an alert.
When you open the amazon_revenue.pipeline file it will show you the created pipeline as below.
1.8.1 How to create a pipeline component
- Open the Launcher (File > New Launcher or “+” in the top left) if it is not already open.
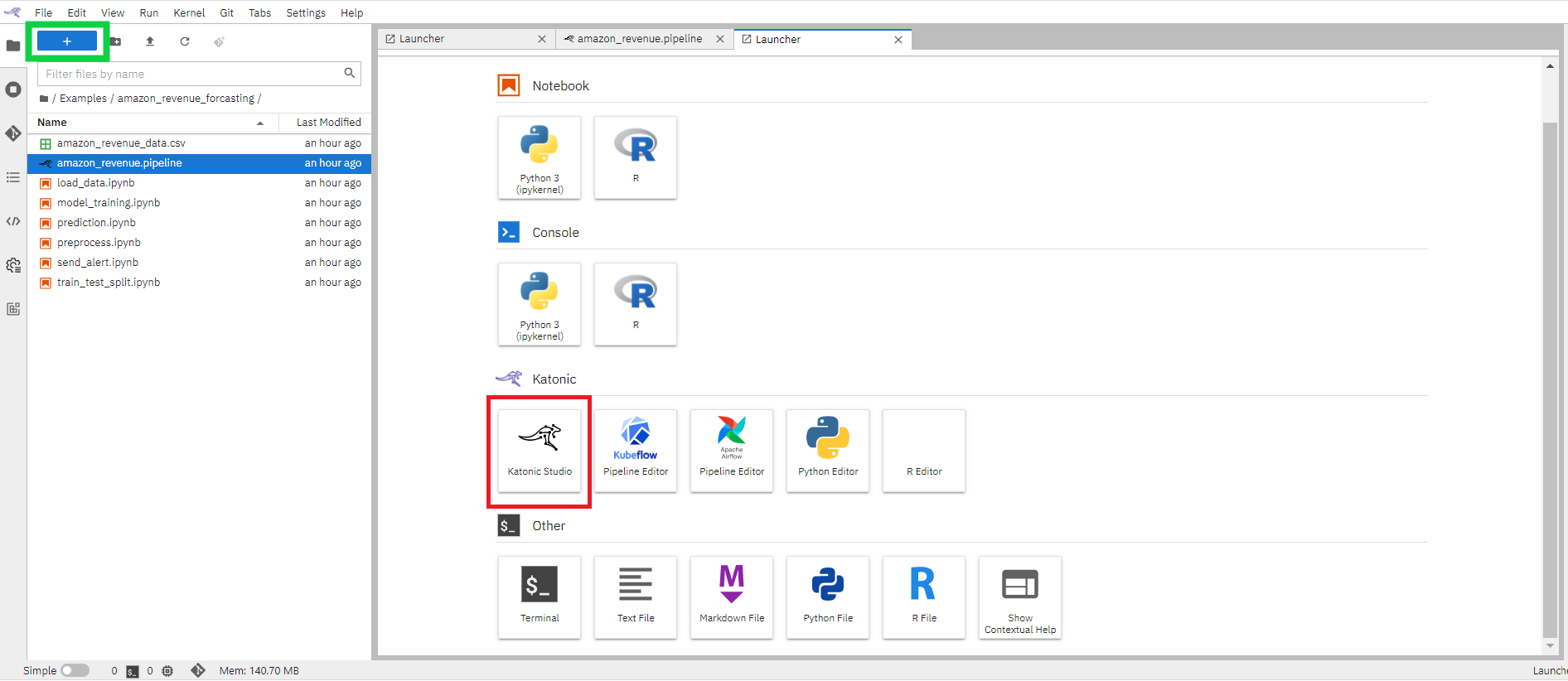
- Open the pipeline editor to create a new untitled generic pipeline. Rename the pipeline to Example.
- In the Visual Pipeline Editor open the properties panel on the right side. Select the Pipeline properties tab and fill in the pipeline details.
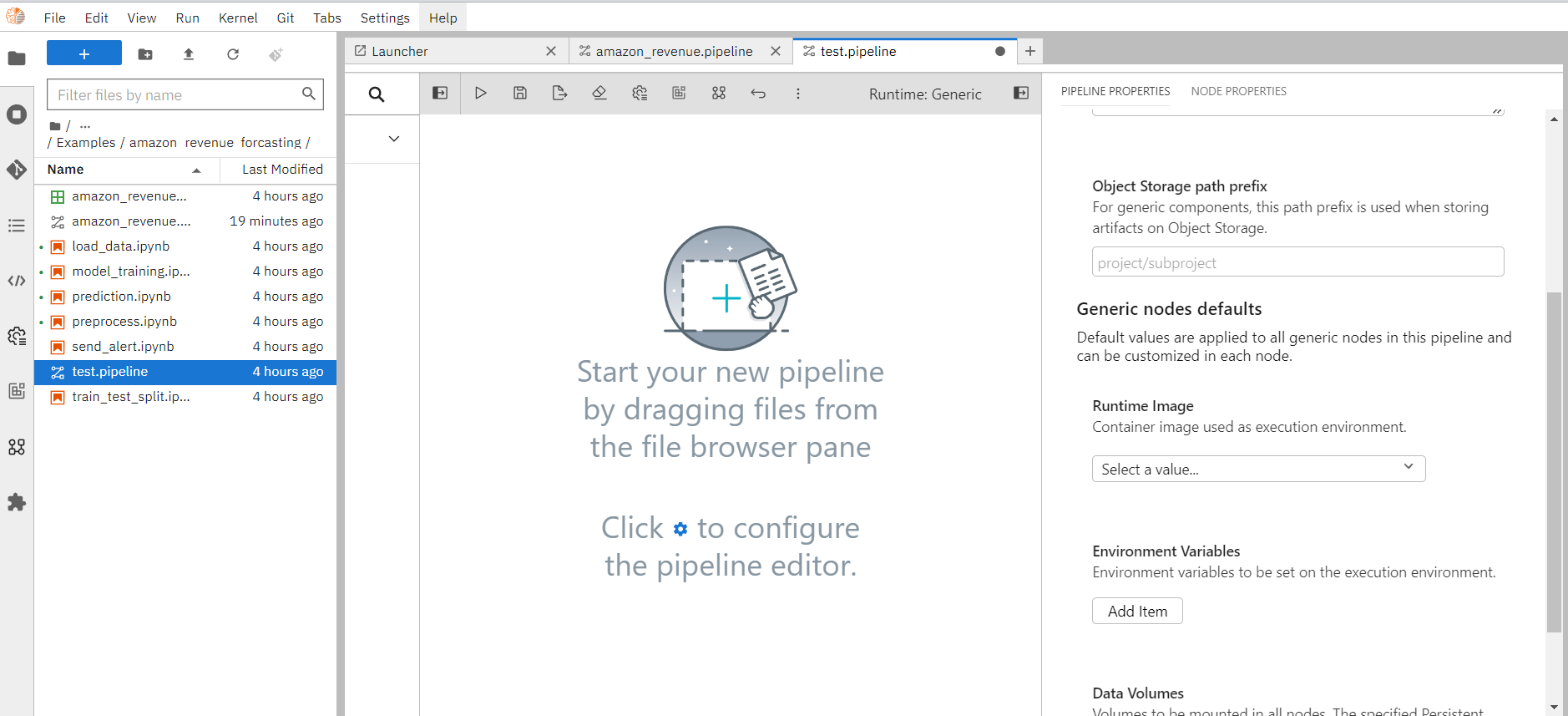
Pipeline Name: Name of the pipeline will appear here.
Pipeline Runtime: A generic pipeline comprises only of nodes that are implemented using generic components. This release includes three generic components that allow for execution of Jupyter notebooks, Python scripts, and R scripts.
Pipeline Description: An optional description summarizing the pipeline purpose.
Object Storage Path Prefix: For generic components, this path prefix is used when storing artifacts on Object Storage.
Runtime Image: As Runtime Image choose “Pandas”. The runtime image identifies the container image that is used to execute the notebook or Python script when the pipeline is run on Kubeflow Pipelines or Apache Airflow. This setting must always be specified, but is ignored when you run the pipeline locally.
Environment Variables: If desired, you can customize additional inputs by defining environment variables.
Data volumes: Volumes to be mounted in all nodes. The specified volume Claims must exist in the Kubernetes namespace where the nodes are executed or the pipeline will not run.
- Expand the component palette panel on the left-hand side. Note that there are multiple component entries, one for each supported file type.
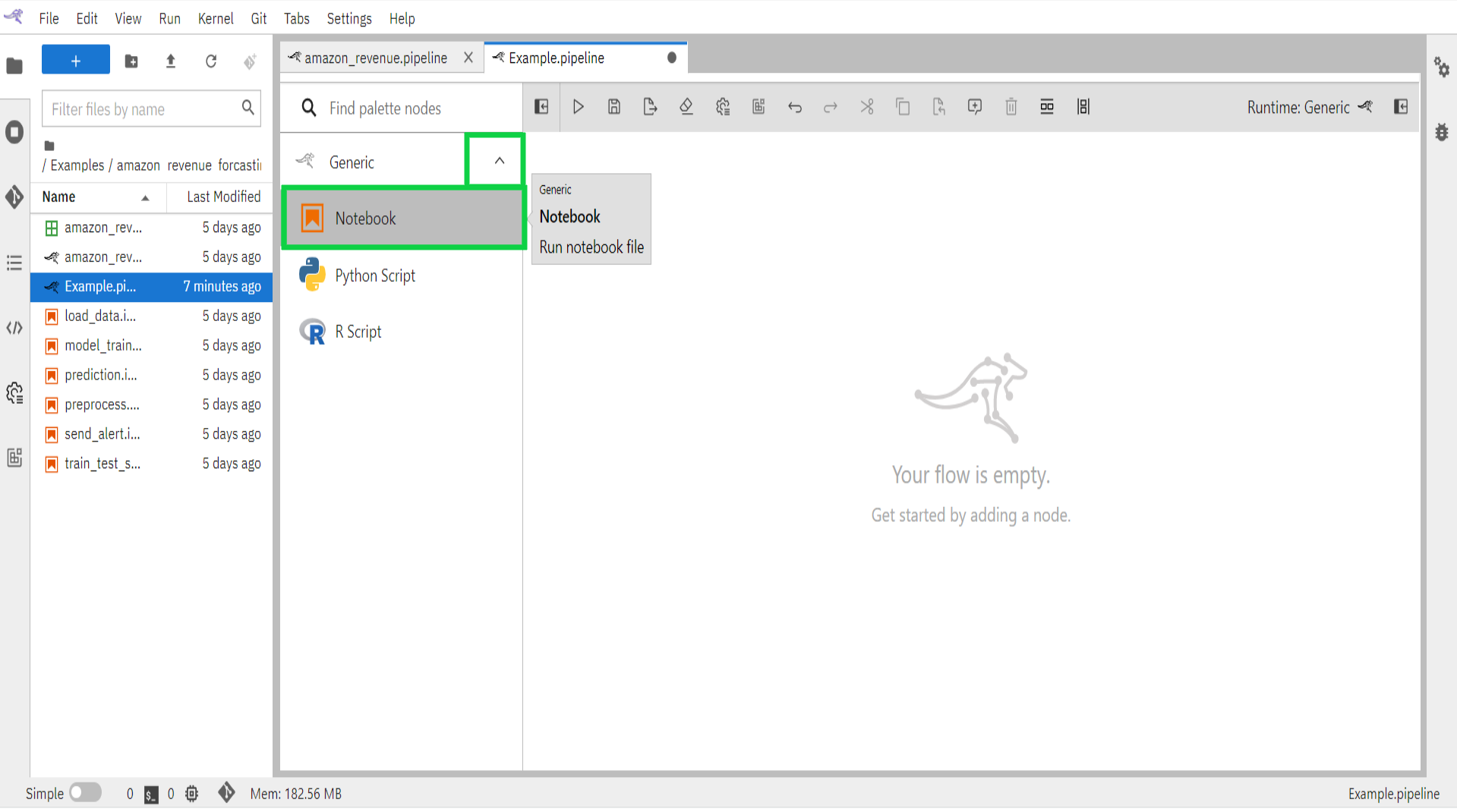
- Drag the notebook component entry onto the canvas (or double click on a palette entry) and hover over the node. The error messages are indicating that the node is not yet configured properly.
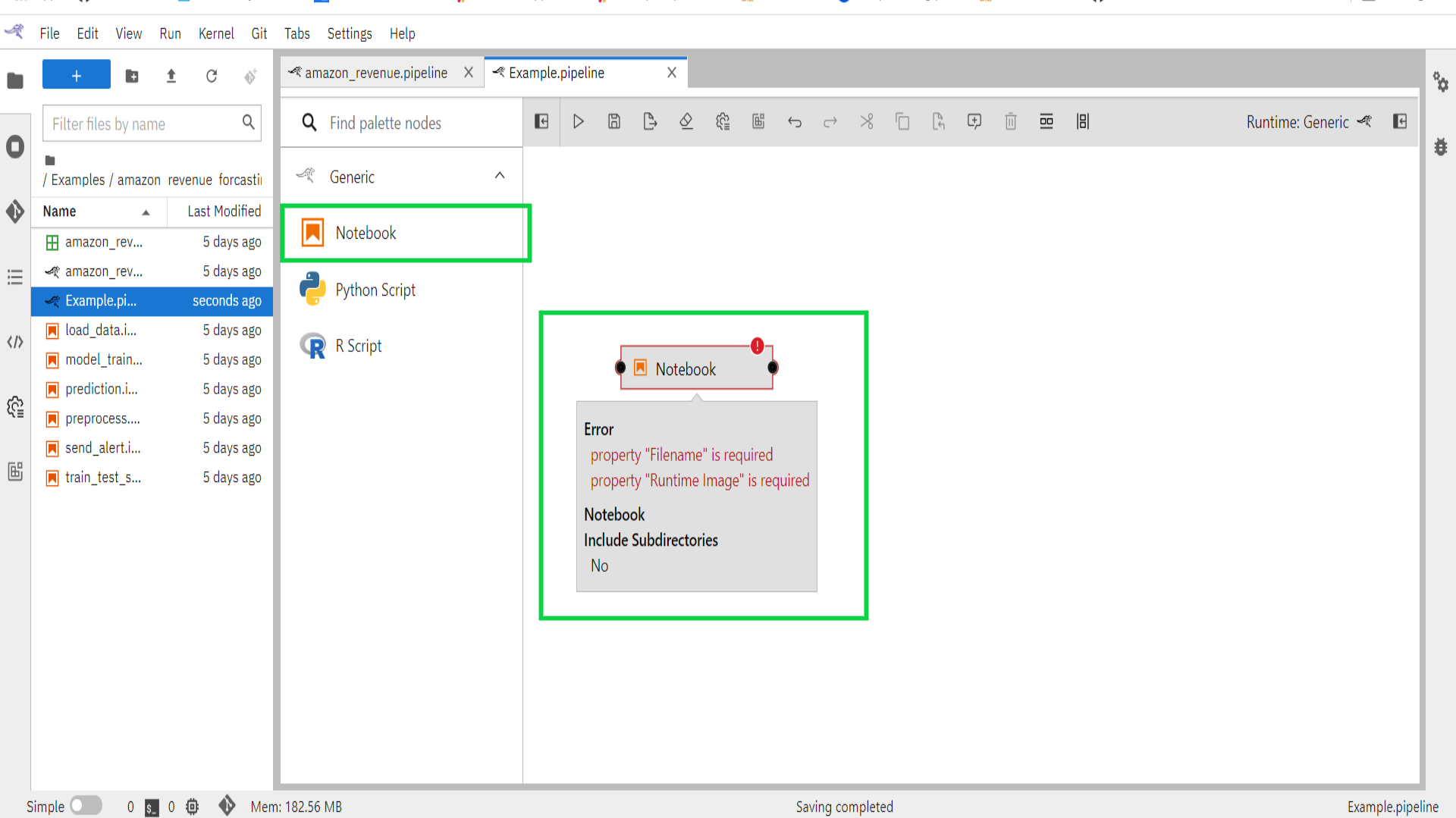
- Select the newly added node on the canvas, right-click, and select Open Properties from the context menu.
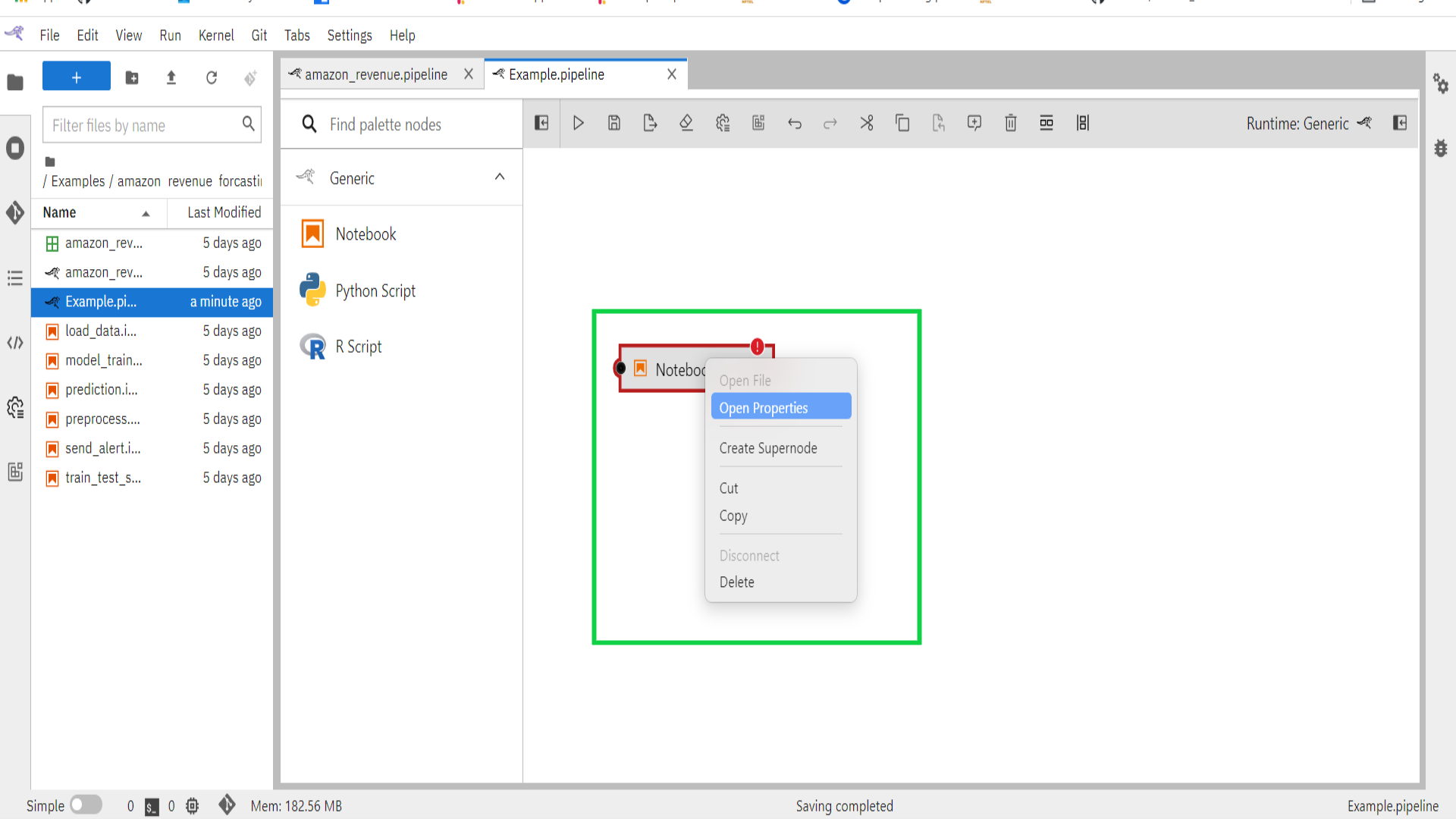
- Configure the node properties.
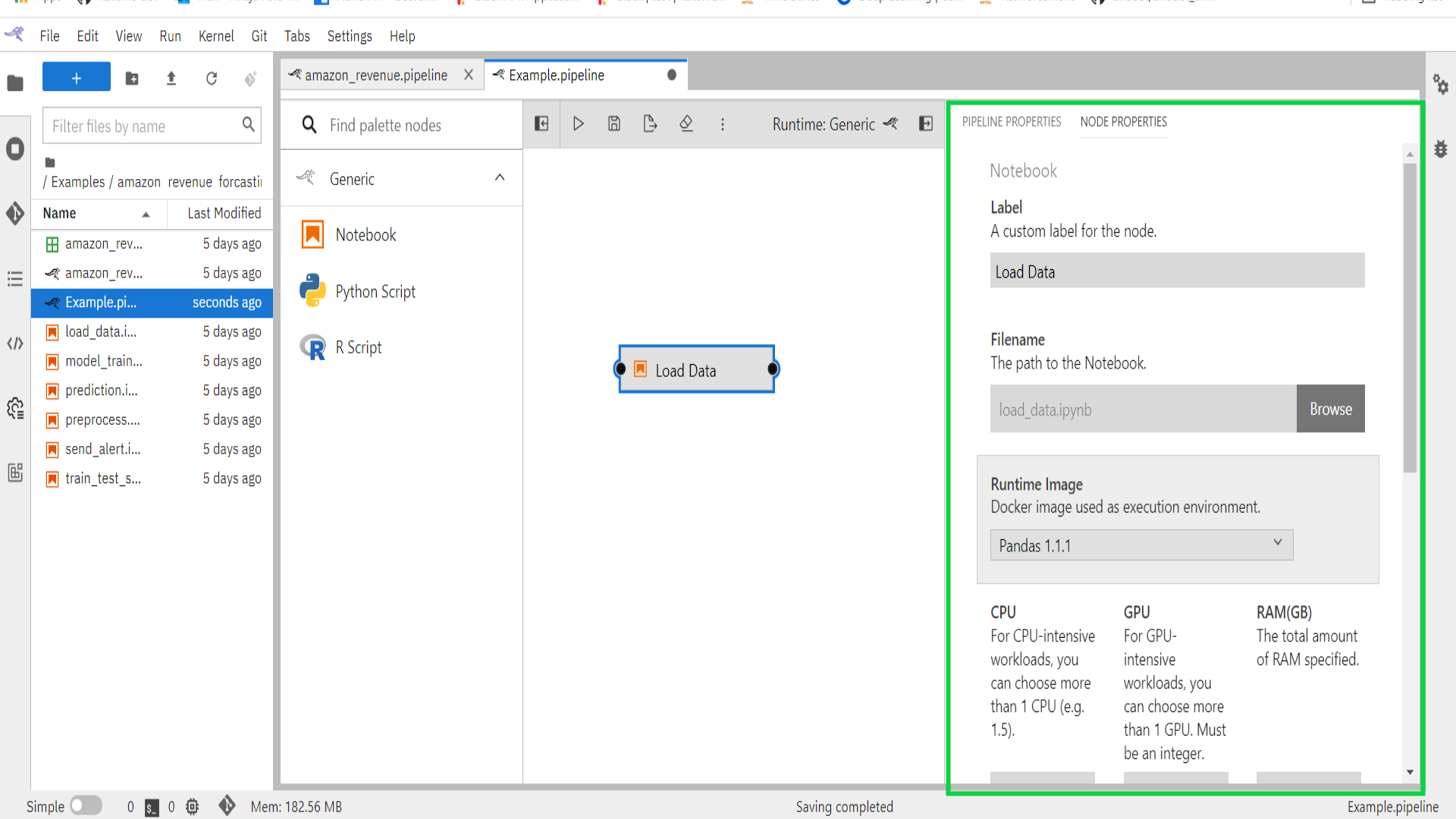
Label: Assign the node a descriptive label. If you leave the label empty, the file name will be used.
Filename: Browse to the file location. Navigate to the “/Examples/amazon_revenue_forcasting/” directory and select “load_data.ipynb”.
Runtime Image: As Runtime Image choose “Pandas”. The runtime image identifies the container image that is used to execute the notebook or Python script when the pipeline is run on Kubeflow Pipelines or Apache Airflow. This setting must always be specified but is ignored when you run the pipeline locally.
CPU/GPU/RAM: If the container requires a specific minimum amount of resources during execution, you can specify them.
File Dependencies: The load_data file does not have any input file dependencies. Leave the input field empty.
Environment Variables: If desired, you can customize additional inputs by defining environment variables.
- For a component, you can comment from the comment button.
Select the component
Click on the comment button on the top
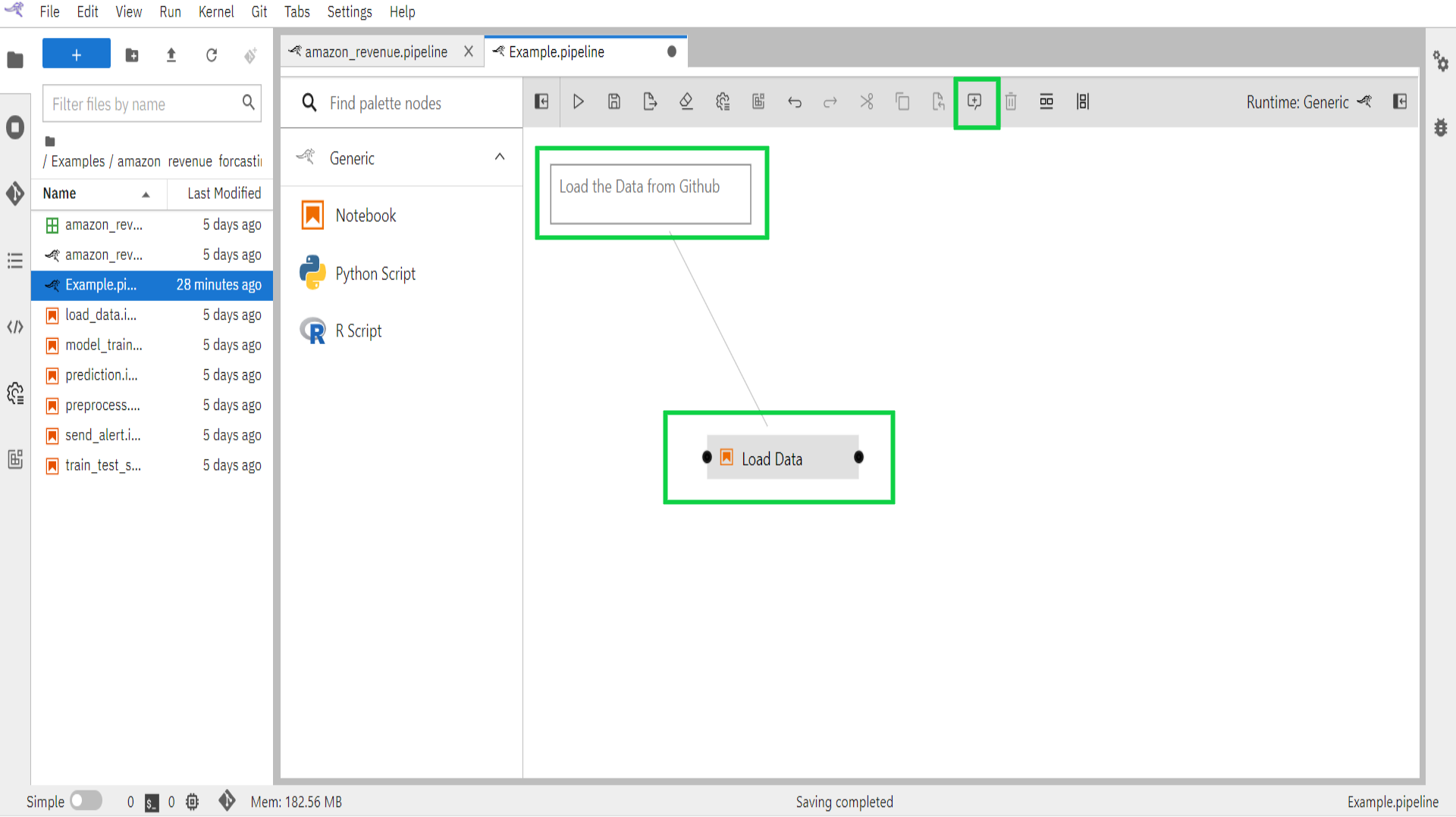
1.8.2 How to connect components
Earlier in this tutorial, you added a (notebook or Python script) file component to the canvas using the palette. You can also add Jupyter notebooks, Python scripts, or R scripts to the canvas by dragging and dropping from the JupyterLab File Browser.
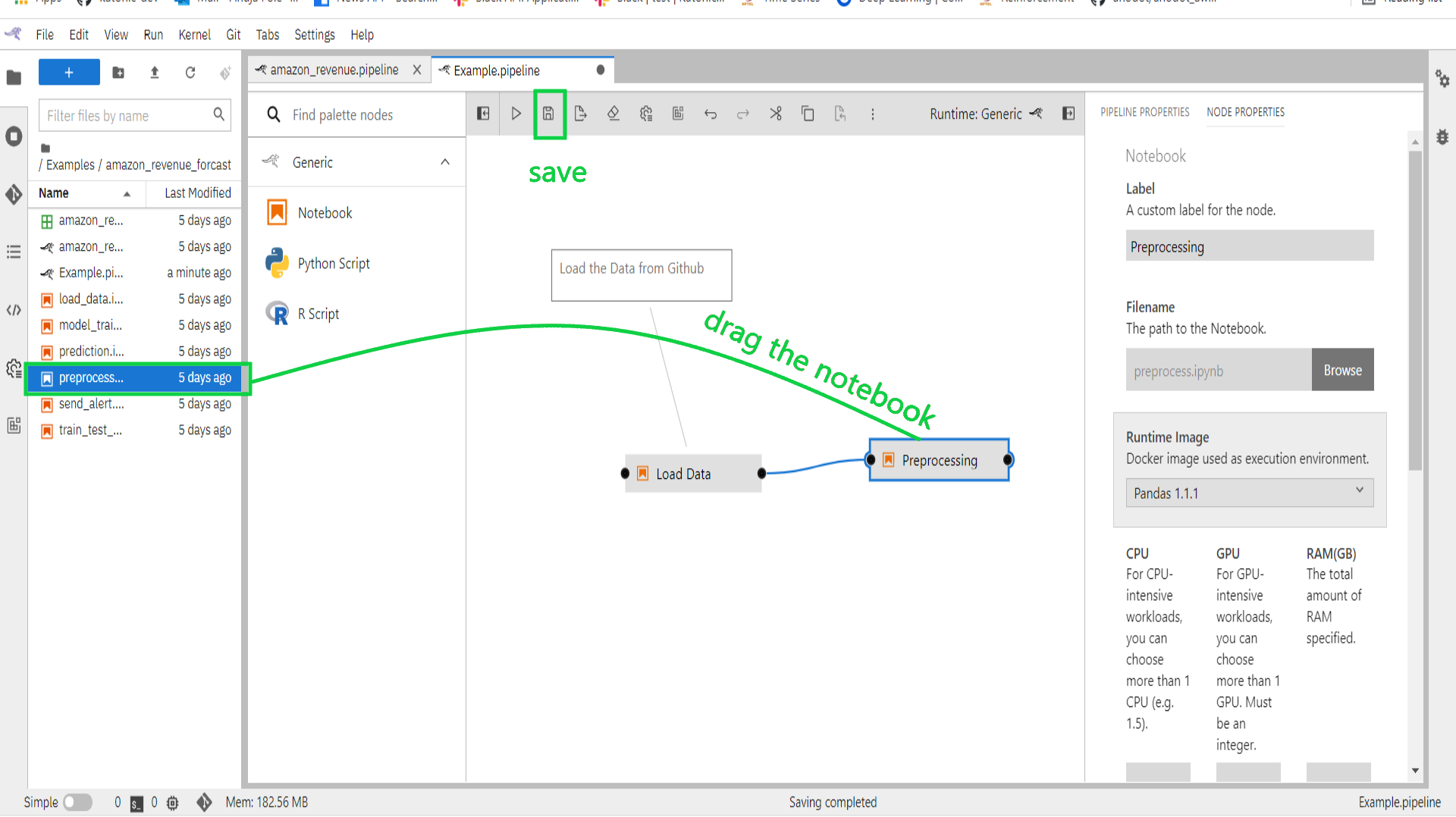
From the JupyterLab File Browser drag and drop the “preprocess.ipynb” notebook from location “/Examples/amazon_revenue_forcasting/“ onto the canvas.
Customize the file's execution properties as follows:
Runtime image: Pandas
Output files: output.csv
Connect the output port of the load_data node to the input port of the preprocessing node to establish a dependency between the two notebooks.
Save the pipeline.
1.8.3 Amazon Revenue pipeline flow
Earlier in the tutorial, we have how to create pipeline components and connect the components. In this section, we will see how the end-to-end Amazon revenue forecasting pipeline is implemented.
- Open “amazon_revenue.pipeline” pre-build pipeline for amazon revenue forecasting use case.
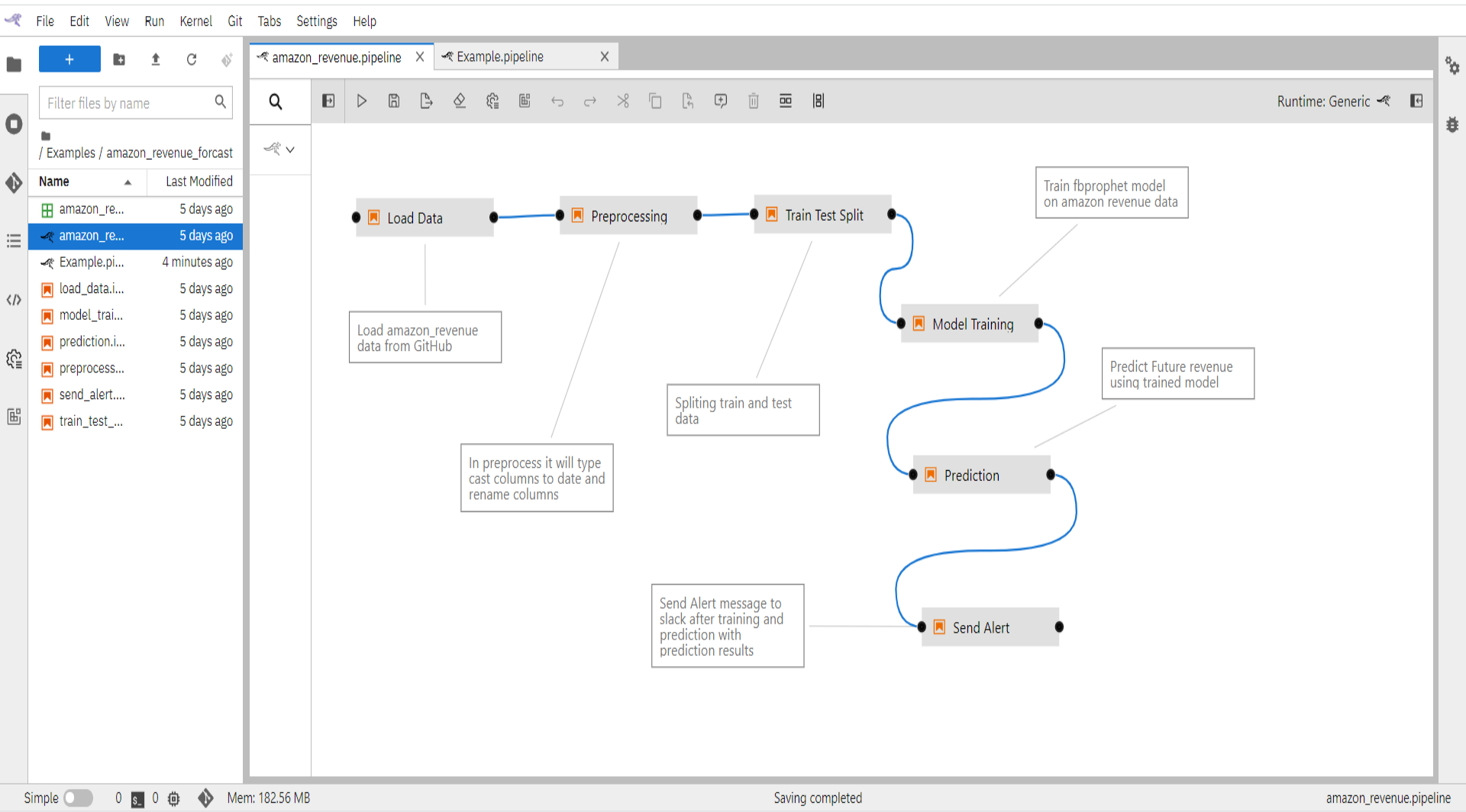
When you double click on any of the components it will open the Jupyter notebook file.
In every component, you should read the output from the previous step and save the results of the current step.
Load Data: Load amazon revenue data from GitHub Link and validate the data. Save the result in the out.csv file
import pandas as pd
# clone amazon revenue data from GitHub
df=pd.read_csv('https://raw.githubusercontent.com/katonic-dev/Examples/master/amazon_revenue_forcasting/amazon_revenue_data.csv')
df.head() # print dataset
df.info() # print info and check null values and data types
# save this step output to a file
df.to_csv("output.csv",index=False)
- Preprocess: Check null values, typecast “Quarter” column to DateTime, rename columns and you can add any type of preprocessing in this file. Save the results in output.csv
import pandas as pd
# read output file of previous step as input of this step
df = pd.read_csv("output.csv")
df.isnull().any() # check if data has any values
df['Quarter']=pd.to_datetime(df['Quarter']) # Type cast Quarter column to datetime
# rename COlumns
df=df.reset_index()[['Quarter','Revenue']].rename({'Quarter':'ds','Revenue':'y'},axis='columns')
# save this step output to a file
df.to_csv("output.csv",index=False)
- Train and Test Split: Split the data into train and test. Data between '2005-03-31' and '2019-03-31' should be into the train, rest into the test. import pandas as pd
# read output file of previous step as input of this step
df = pd.read_csv("output.csv")
# Split data into train and test
# Train : data between '2005-03-31' and '2019-03-31'
# Test : data after '2019-03-31'
train=df[(df['ds']>='2005-03-31')&(df['ds']<='2019-03-31')]
test=df[df['ds']>'2019-03-31']
# Print Shape
train.shape
test.shape
# Save train and test into a file
train.to_csv("train.csv",index=False)
test.to_csv("test.csv",index=False)
- Model Training: Install fbprophet package since it is not available in the base python image. Or can also add a new image that contains fbprophet package from “Runtime Image” and add that image to the component. Train fbprophet model with amazon revenue data
import os
# install packages fbprophet which is not available in base image
os.system("pip install pystan==2.19.1.1 fbprophet")
# import packages
from fbprophet import Prophet
import pandas as pd
import pickle
#load train data saved in previous step
train = pd.read_csv("train.csv")
# Train Prophet model with train data
model=Prophet(interval_width=0.95)
model.fit(train)
# Save Trained model into a pickle file
with open("model.pkl", "wb") as f:
pickle.dump(model, f)
- Prediction: Install fbprophet package since it is not available in the base python image. Or can also add a new image that contains fbprophet package from “Runtime Image” and add that image to the component. Load the model that is trained and predict the future revenue.
import os
# install packages fbprophet which is not available in base image
os.system("pip install pystan==2.19.1.1 fbprophet")
import pandas as pd
import pickle
from fbprophet import Prophet
# Load model stored in previous step
with open("model.pkl", "rb") as f:
model = pickle.load(f)
# prediction of future revenue using the trained model
future=model.make_future_dataframe(periods=4,freq='Q') #as the time stamp is Quaterly & 4 is for test data records
forecast=model.predict(future)
forecast[['ds','yhat','yhat_lower','yhat_upper']].head()
# Store end results into file
forecast.to_csv("output.csv",index=False)
- Send Alert: Send an alert message to slack with the prediction results.
import os
os.system("pip install slack slackclient")
from slack import WebClient
from slack.errors import SlackApiError
token = "Your Slack Token"
channel = 'Your communication channel'
text = "Model is trained and future revenue generation is predicted."
file = "output.csv"
title = "Amazon Revenue"
client = WebClient(token=token)
try:
response = client.chat_postMessage(
channel=channel,
text=text)
response = client.files_upload(
channels=channel,
file=file,
title=title
)
except SlackApiError as e:
# You will get a SlackApiError if "ok" is False
assert e.response["ok"] is False
assert e.response["error"] # str like 'invalid_auth', 'channel_not_found'
print(f"Got an error: {e.response['error']}")
- Now pipeline is built and ready. Save the pipeline to run.
1.9 Run Pipeline
In the previous section, we have seen how the generic pipeline and amazon revenue forecasting pipeline is built. In this section, you will learn how to run a pipeline in the Kubeflow runtime environment.
- Run pipeline from the button available on the top bar.
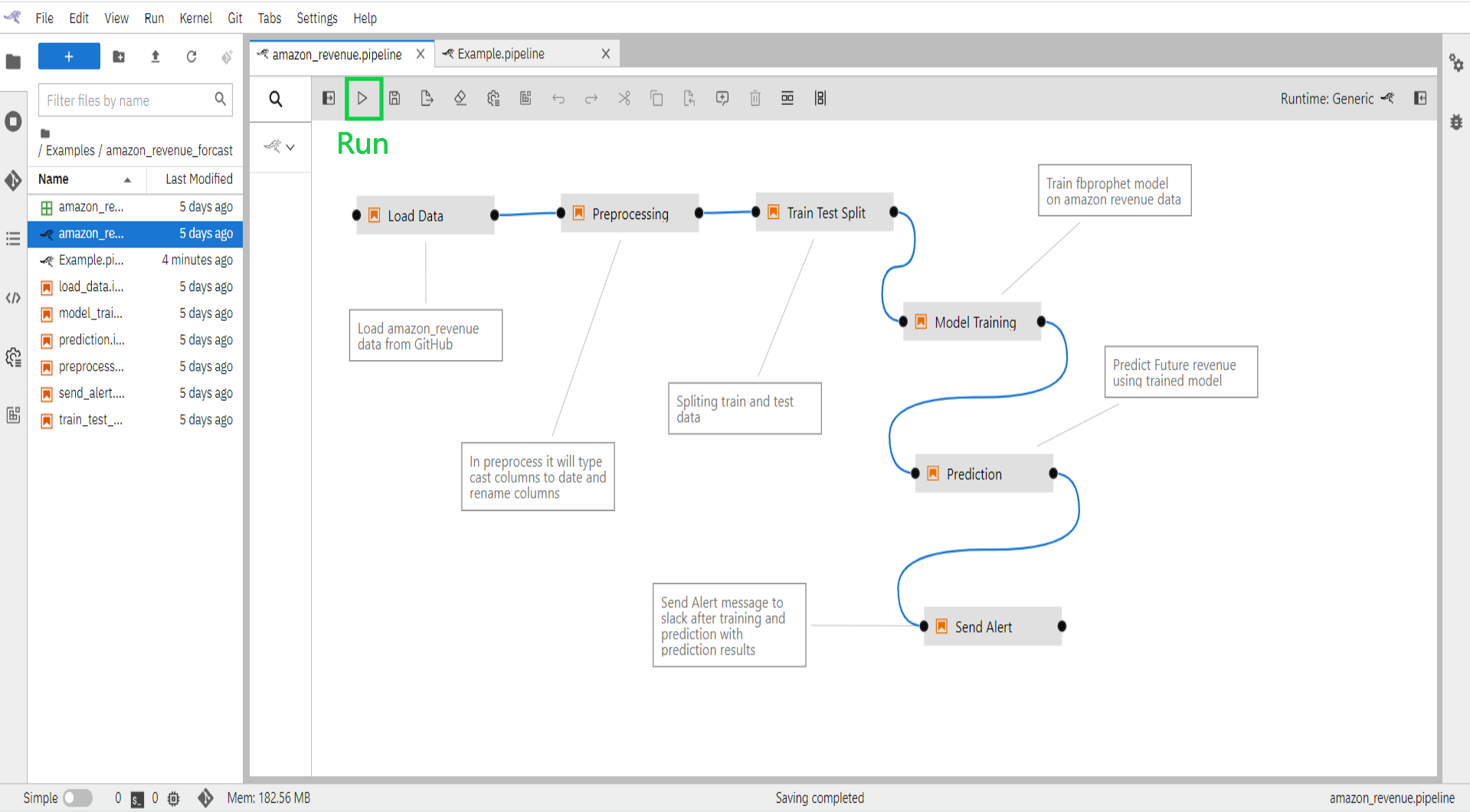
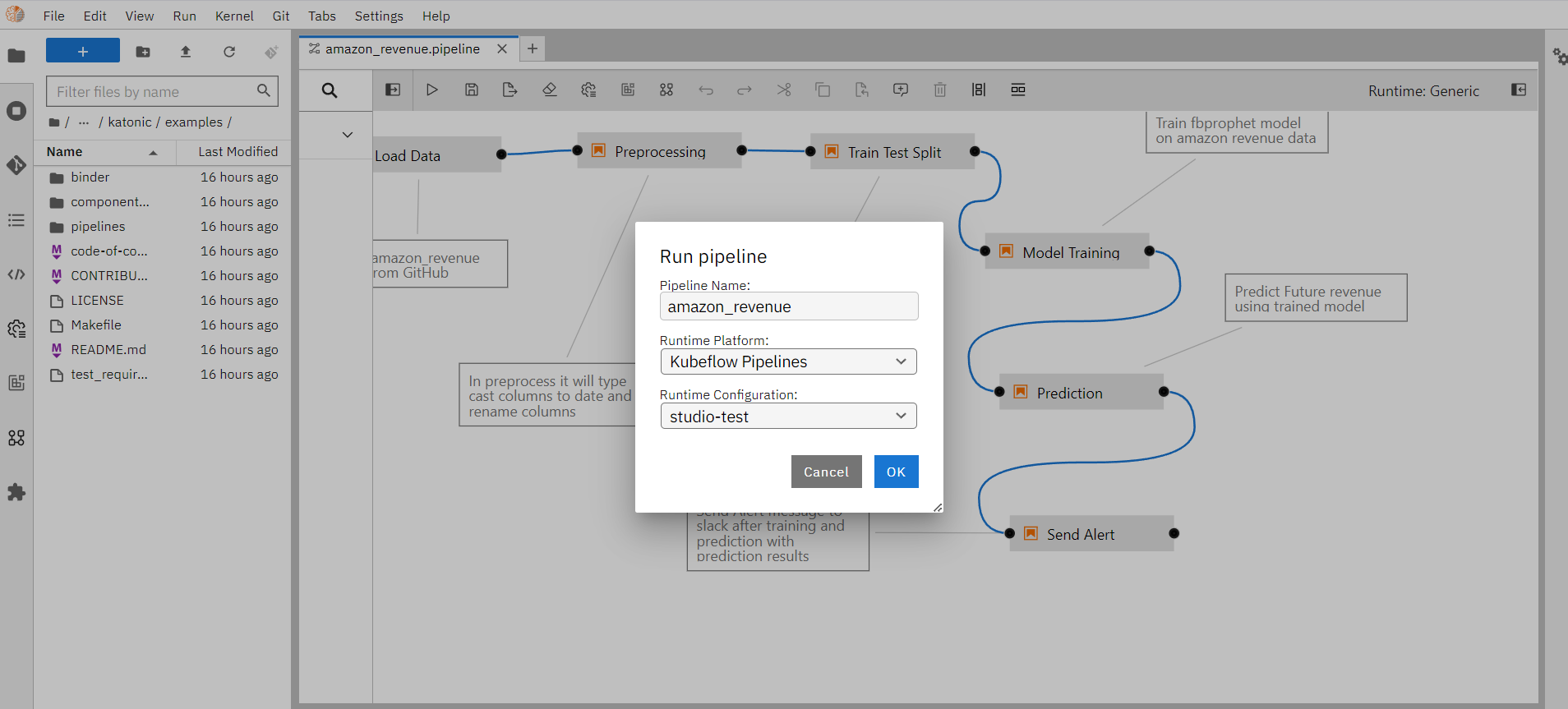
- Enter pipeline name (eg: amazon_revenue), select Runtime Platform as Kubeflow Runtime, and click on the “OK” button.
- Pipeline id now submitted to Kubeflow environment. Click on “OK”.
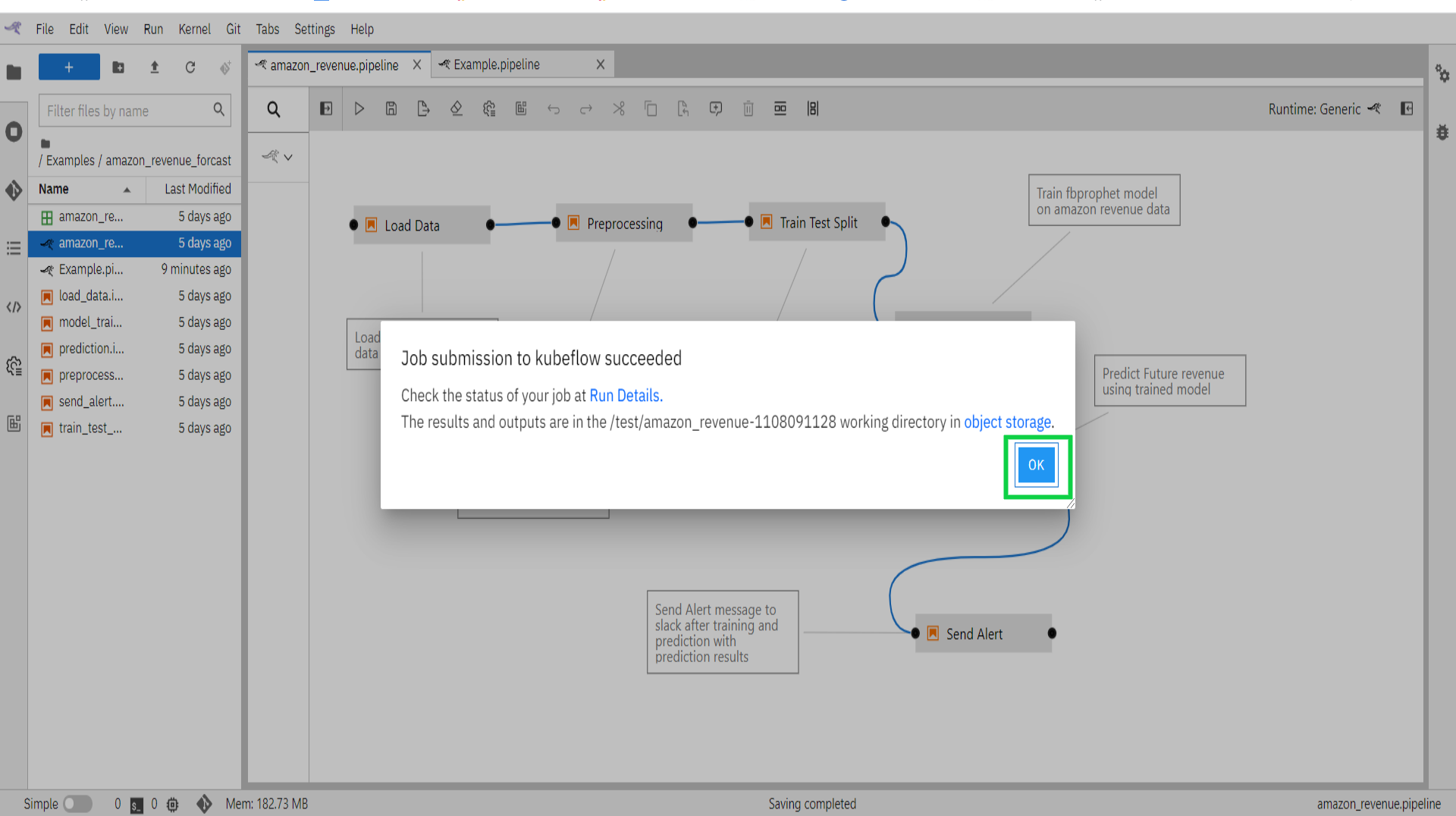
- The pipeline will run in the Kubeflow environment. You can see the pipeline in Pipeline on left panel the platform.
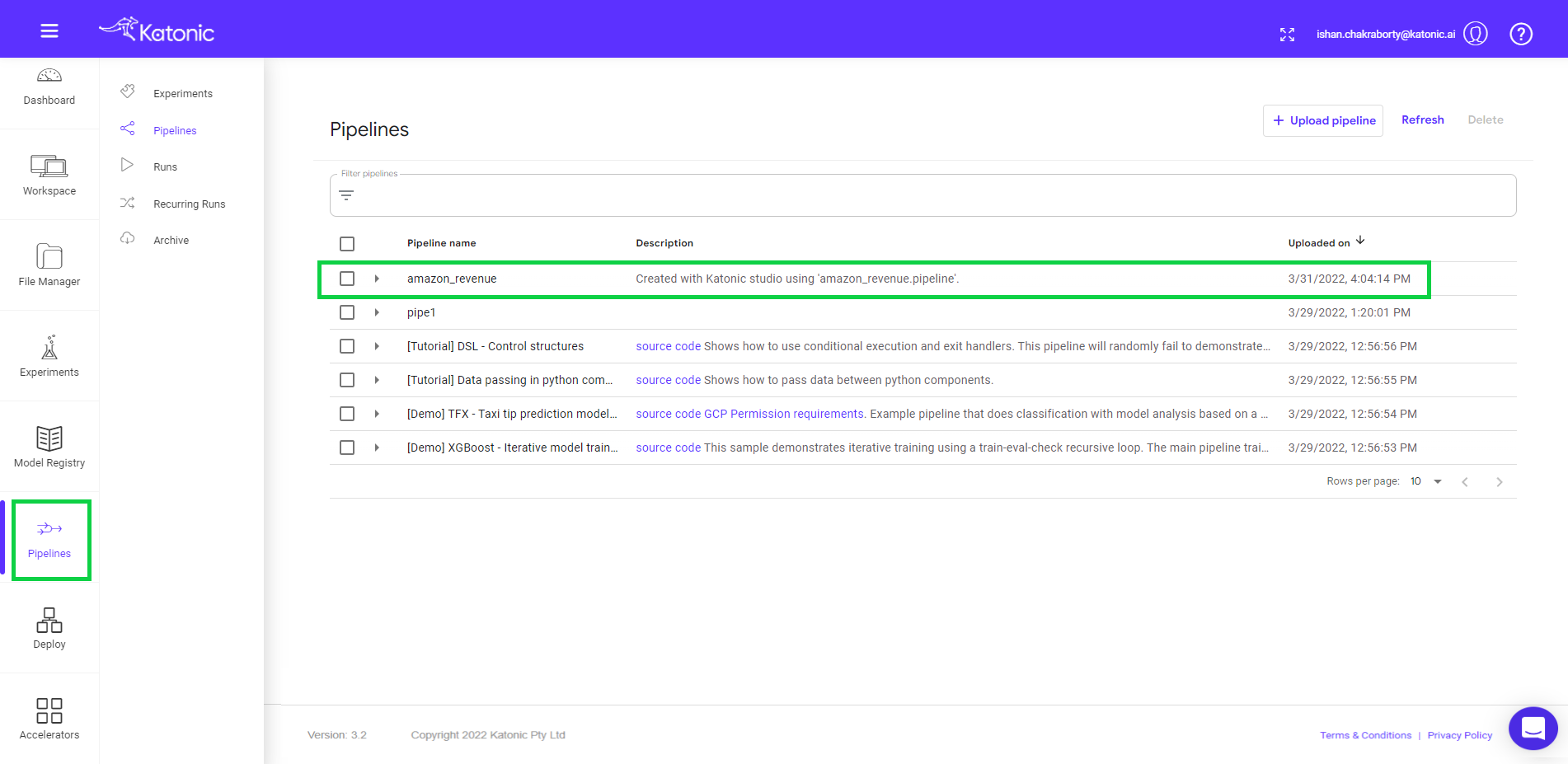
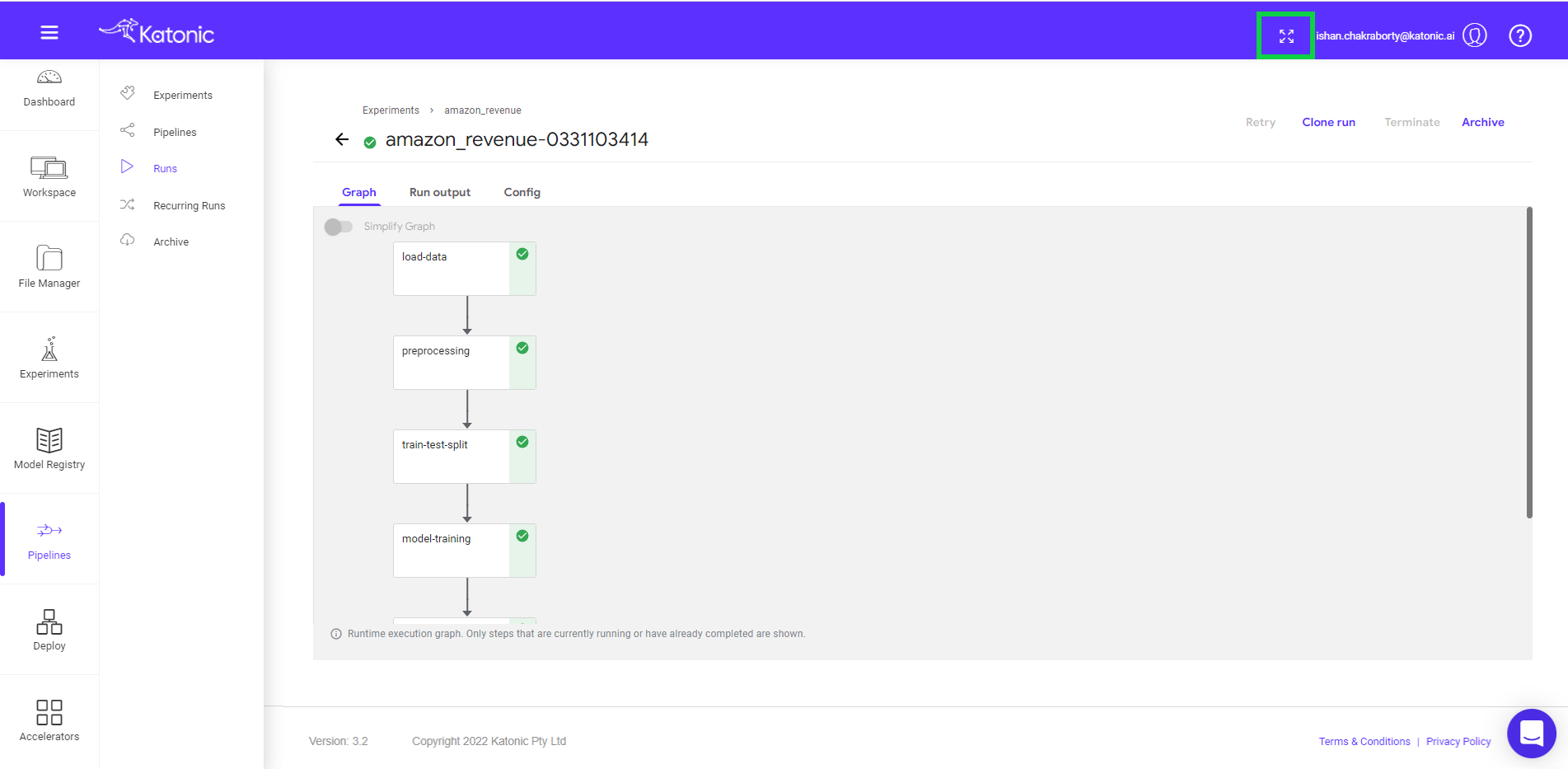
- Click on the pipeline to view the complete pipeline. The pipeline status is in Running. Once all the components run it will show the status in green. Note: To view the pipeline clearly use “full screen” mode (button available on the top right).
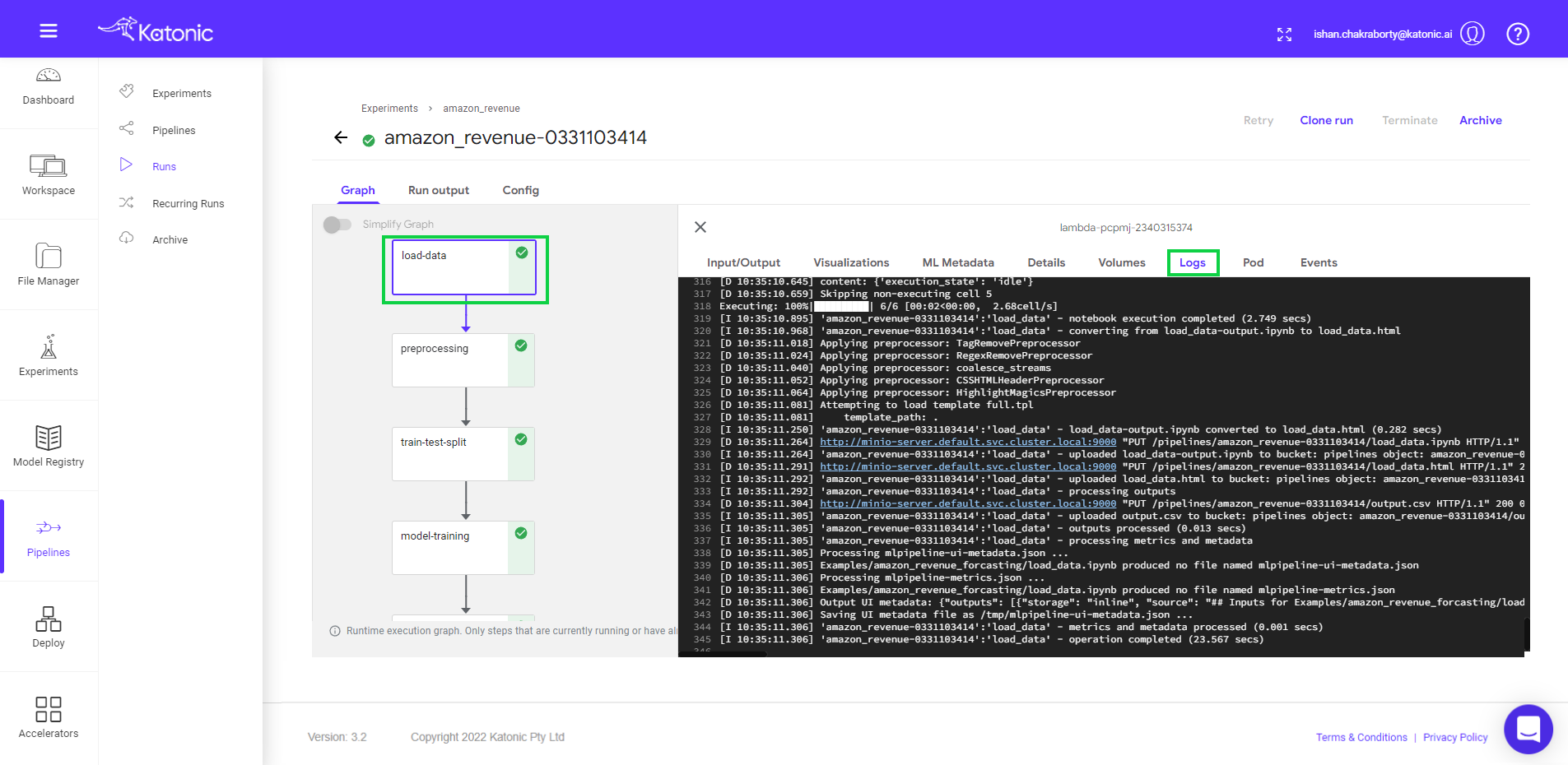
- Click on the component to see the logs and visualizations of the current step.
1.10 Schedule Pipeline
In the previous section, we have seen how to run the Kubeflow pipeline. In this section, you will learn how to schedule this pipeline or re-run the same pipeline again.
- Go to Runs in the left sidebar.
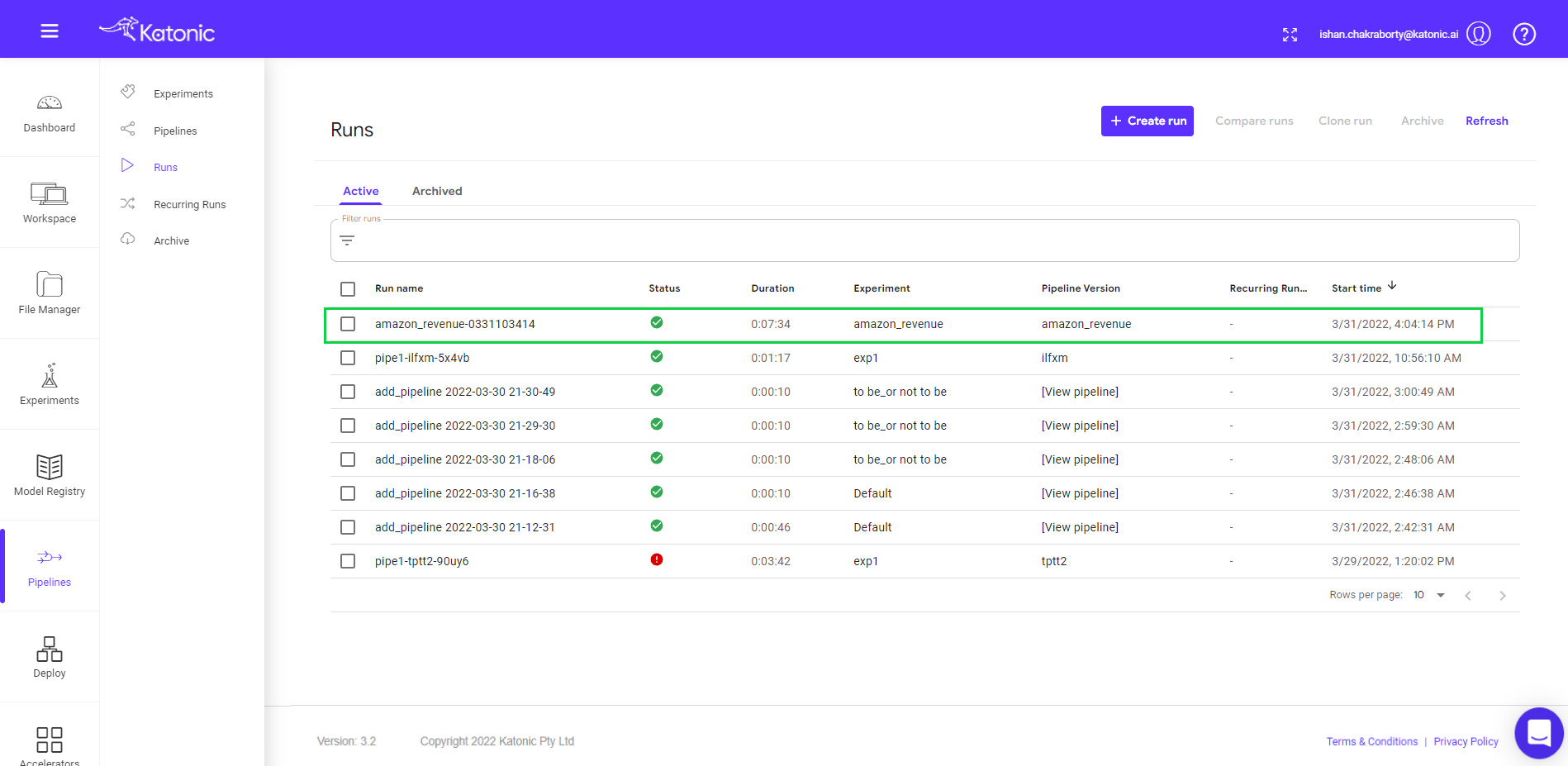
- Click on “Create Run” to run the pipeline or schedule the pipeline.
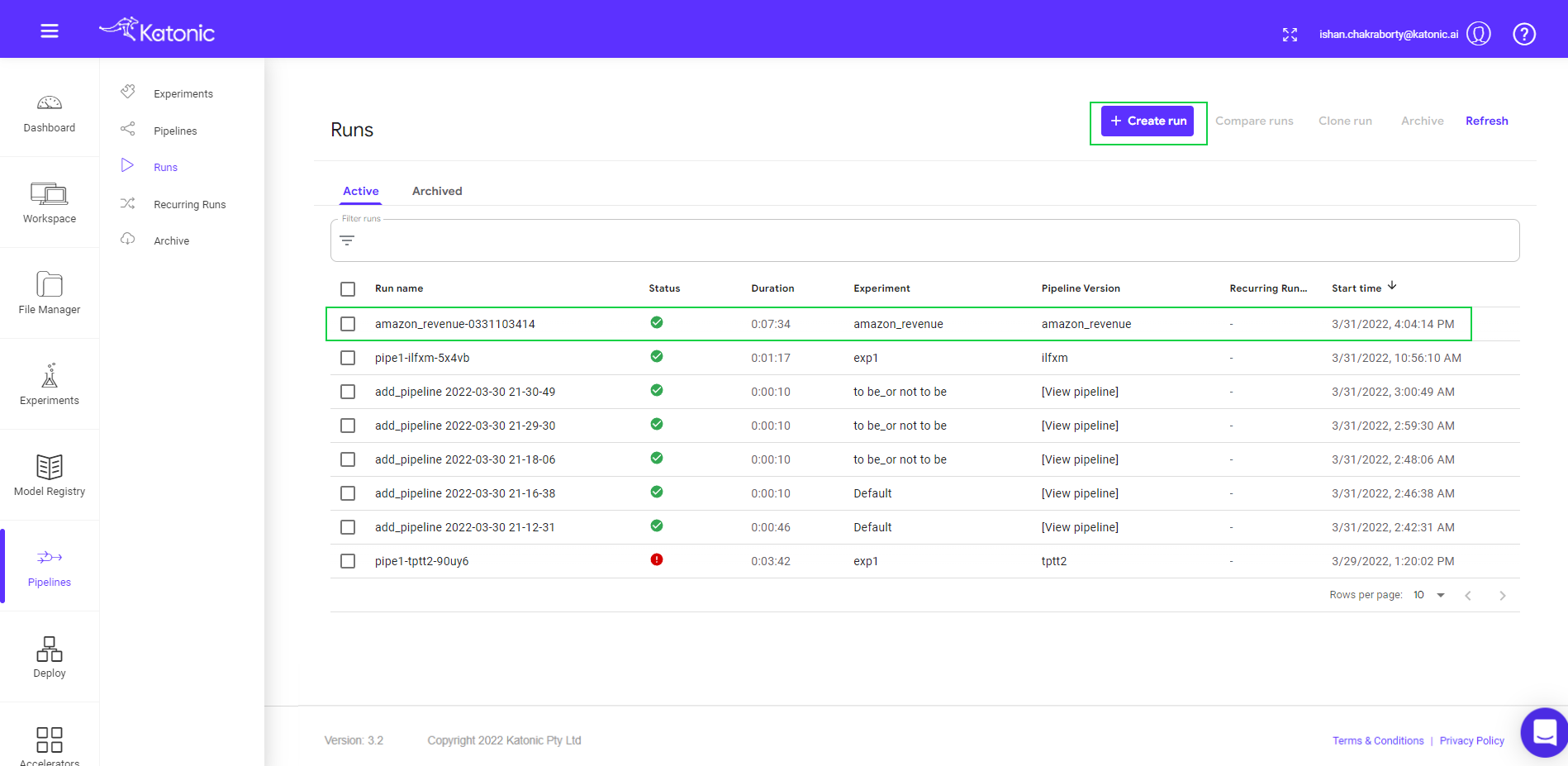
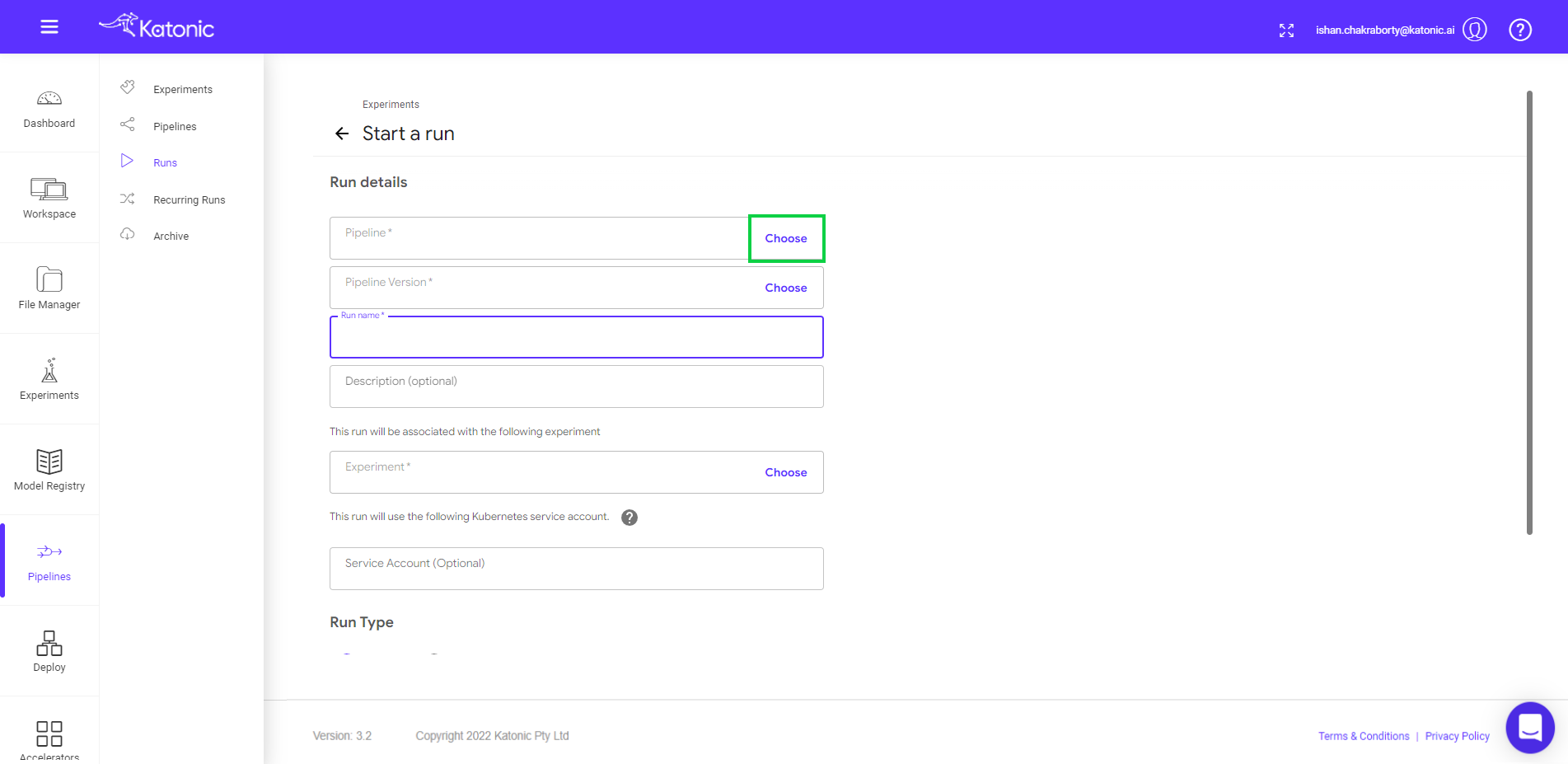
- Click on Choose in the pipeline text box.
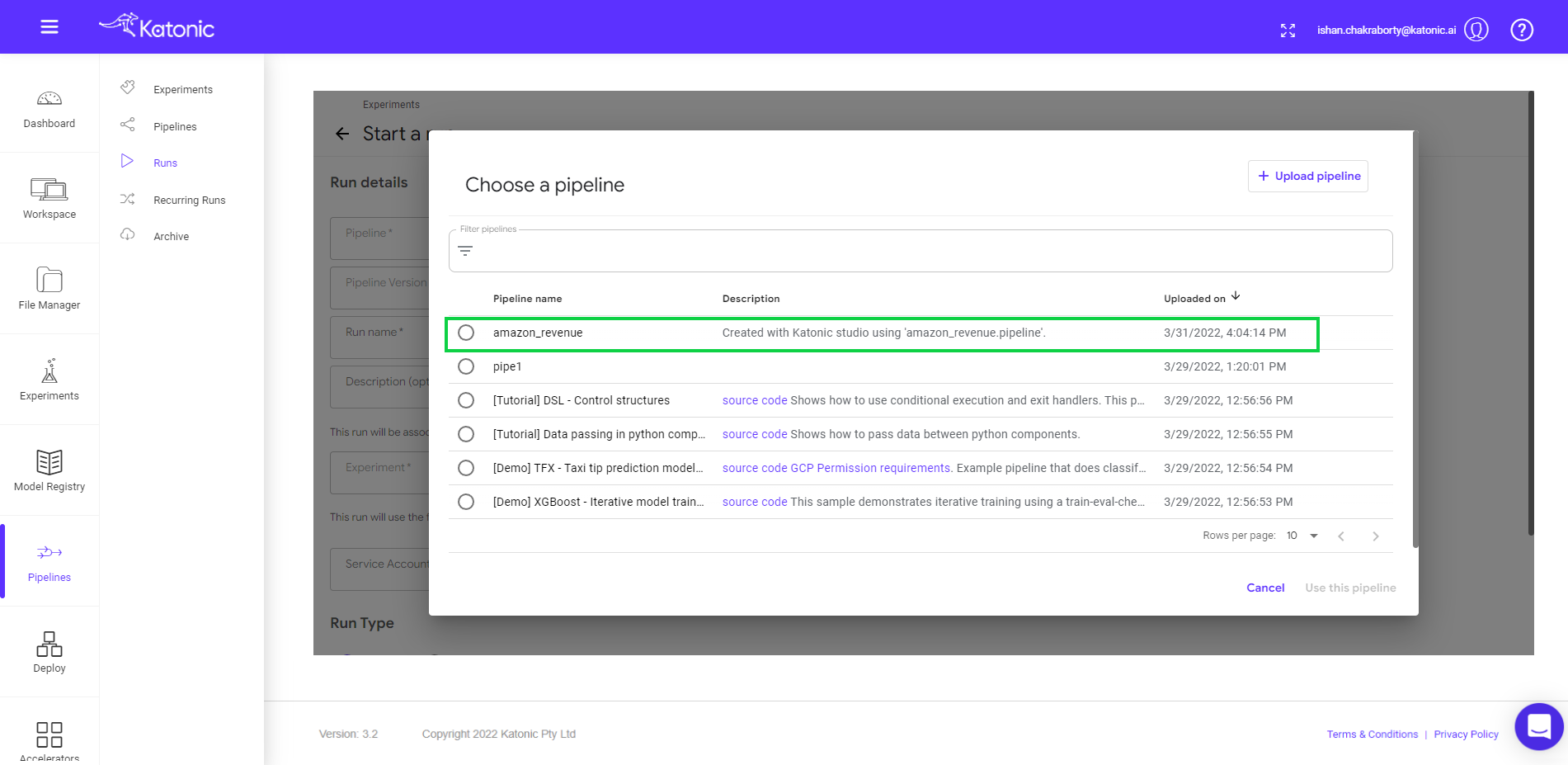
- Select a pipeline that you want to run or schedule (Eg: amazon_revenue). Click on the “Use this pipeline” button.
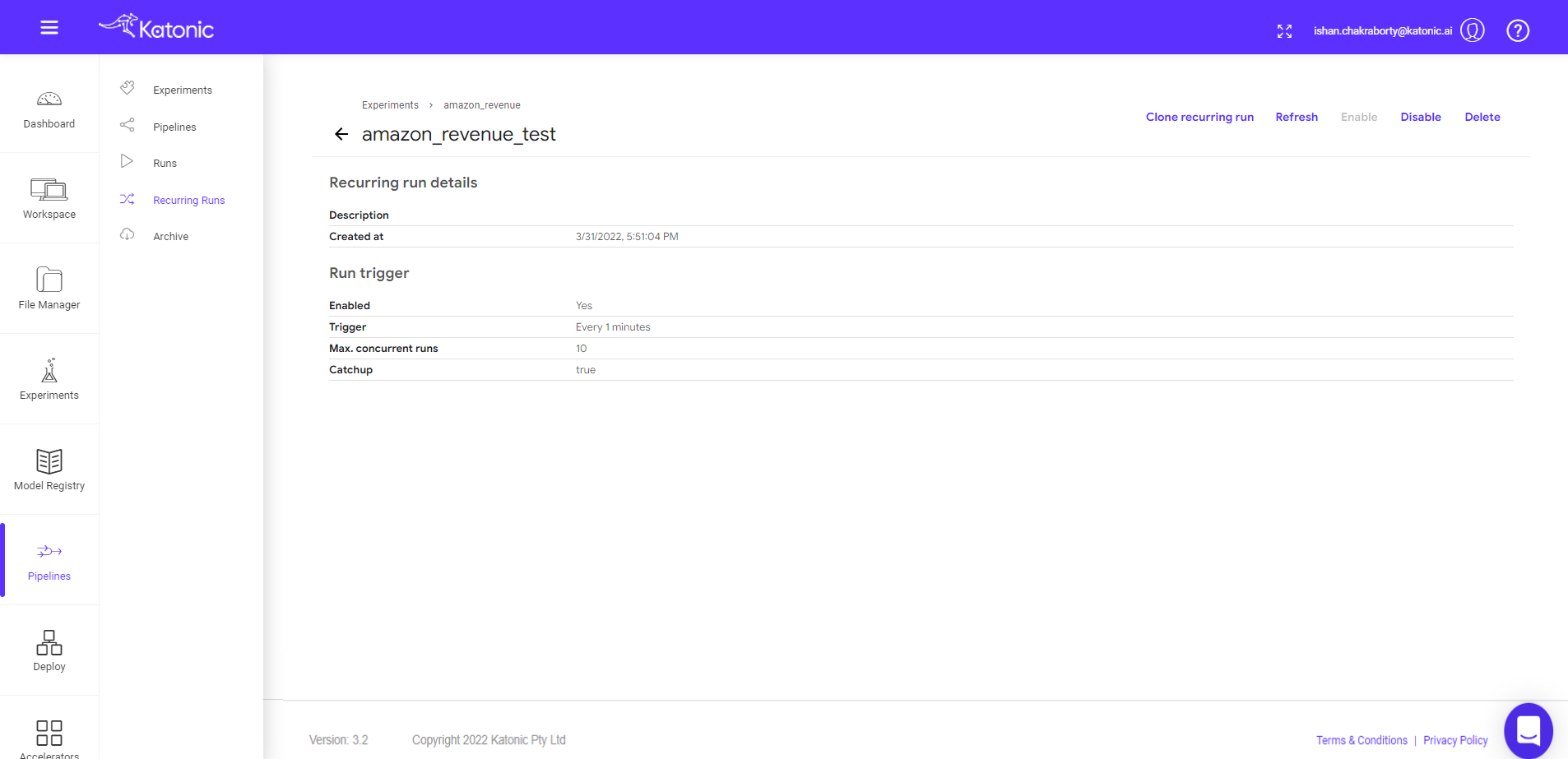
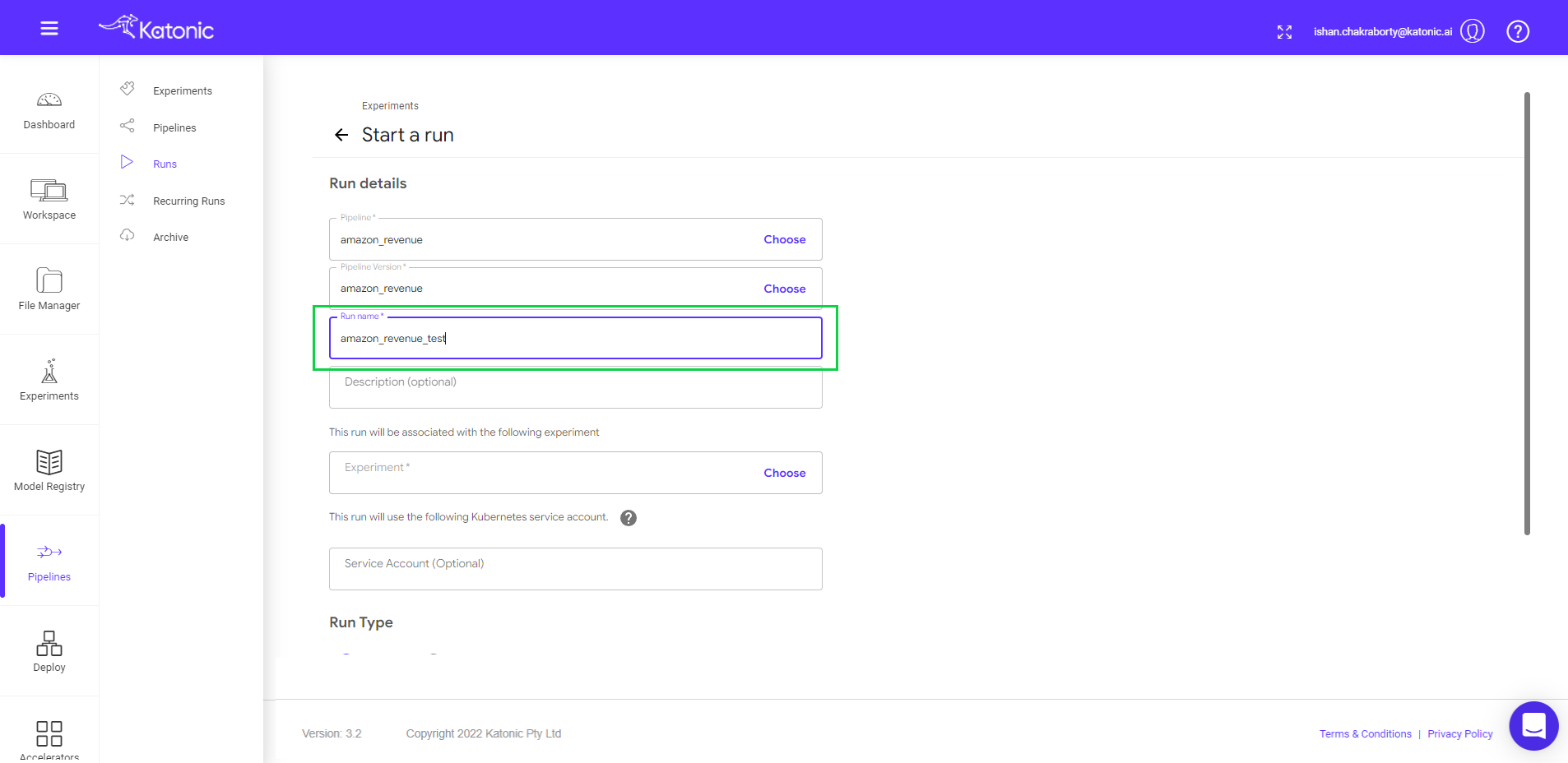
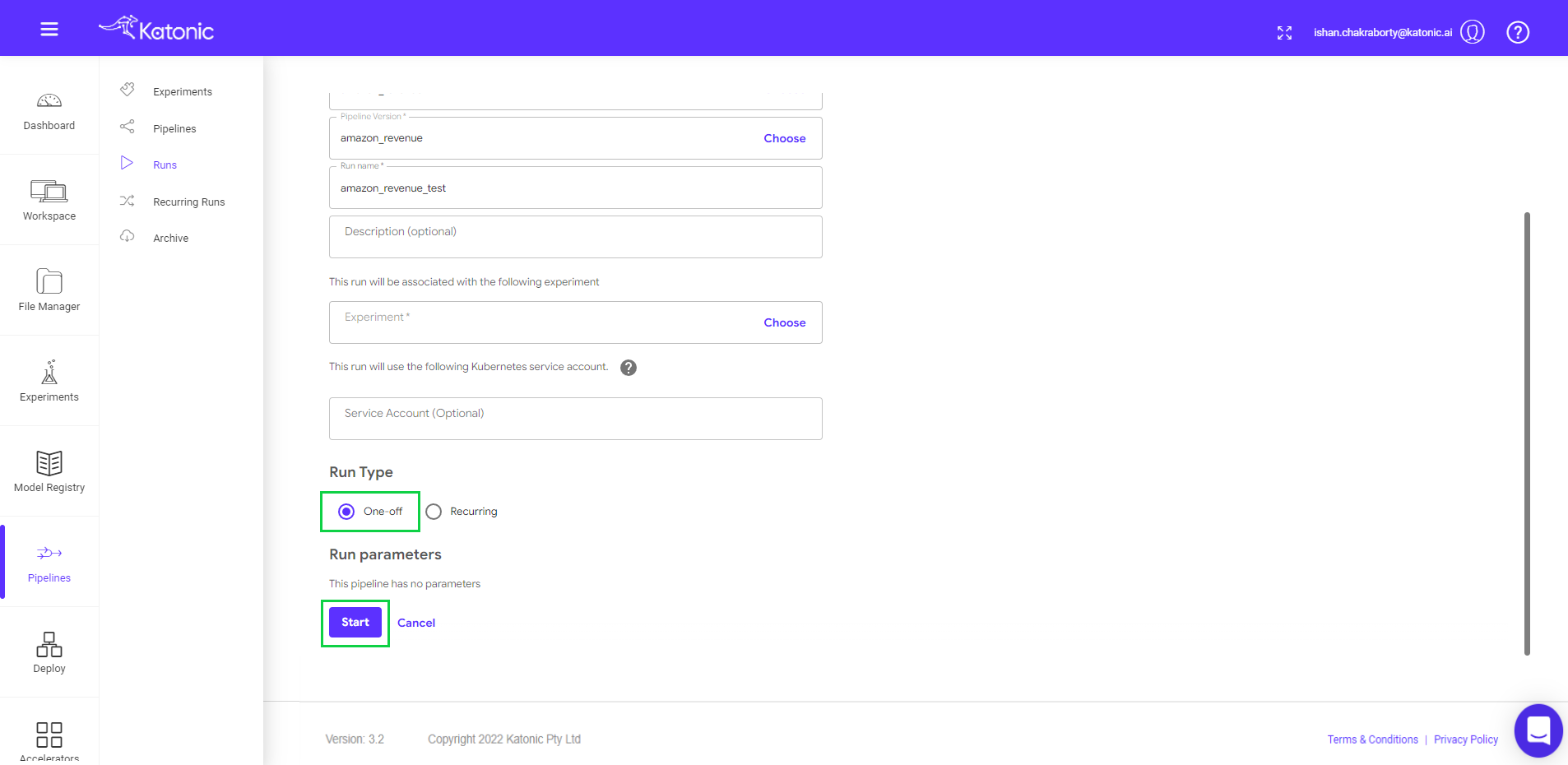
- Give a new Run Name (Eg: amazon_revenue_test). Also choose the respective experiment name under which you have performed your run.
- The pipeline can be run in two ways i.e., run once or schedule
- Run Once: Select Run Type as One-off radio button and click on start to run the pipeline.
- Scheduling: Select Run Type as Recurring.
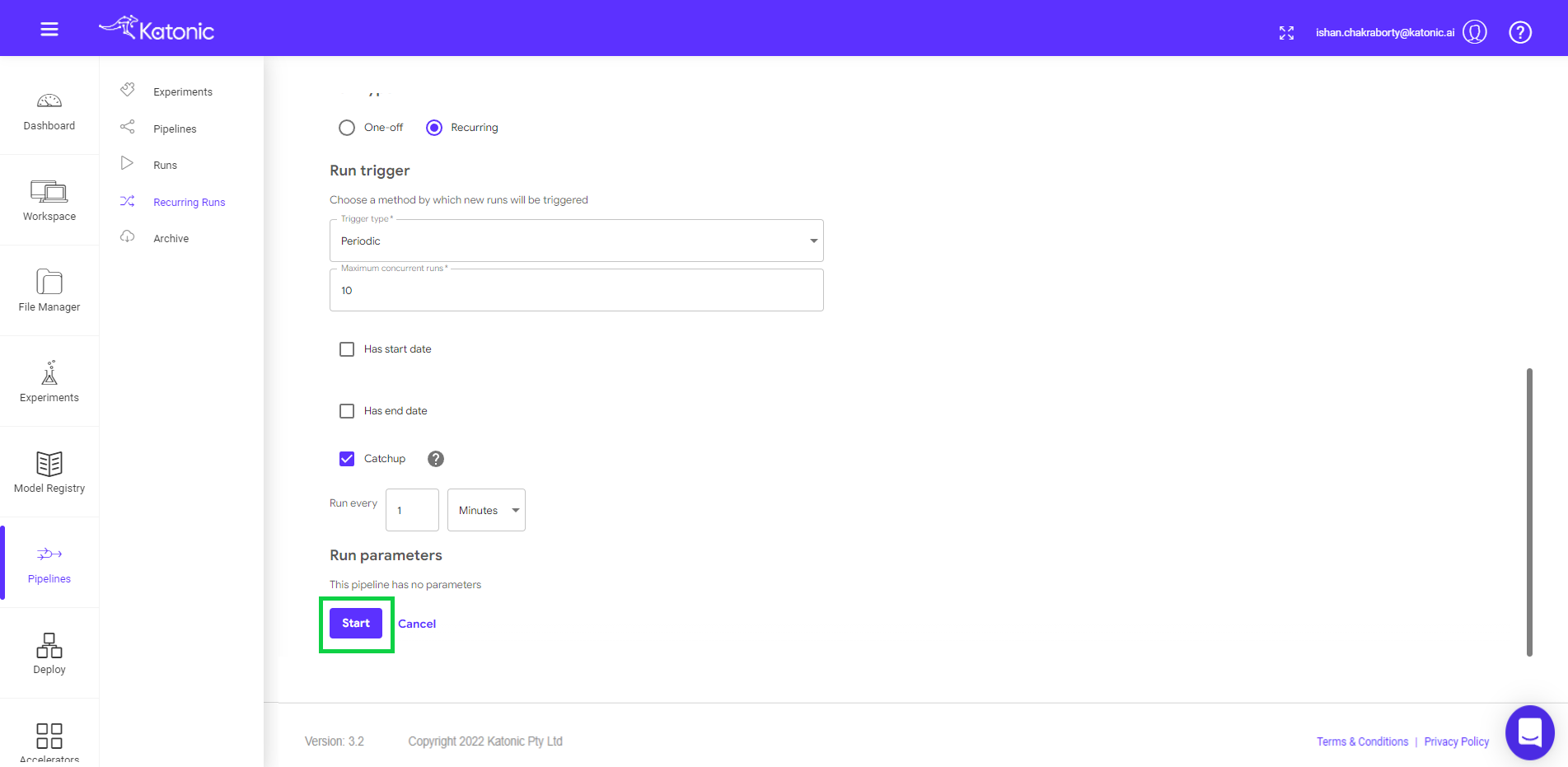
- Trigger Type: Select if the pipeline should run as a Periodic or cron Job.
- Maximum Concurrent Runs: limit the number of runs launched in parallel
- Start Date and End Date: Give the start and end date of the scheduler (Optional)
- Catchup: Specify how many runs every minute/hour/day/week/month.
- Scheduled runs can be seen here in the experiments.
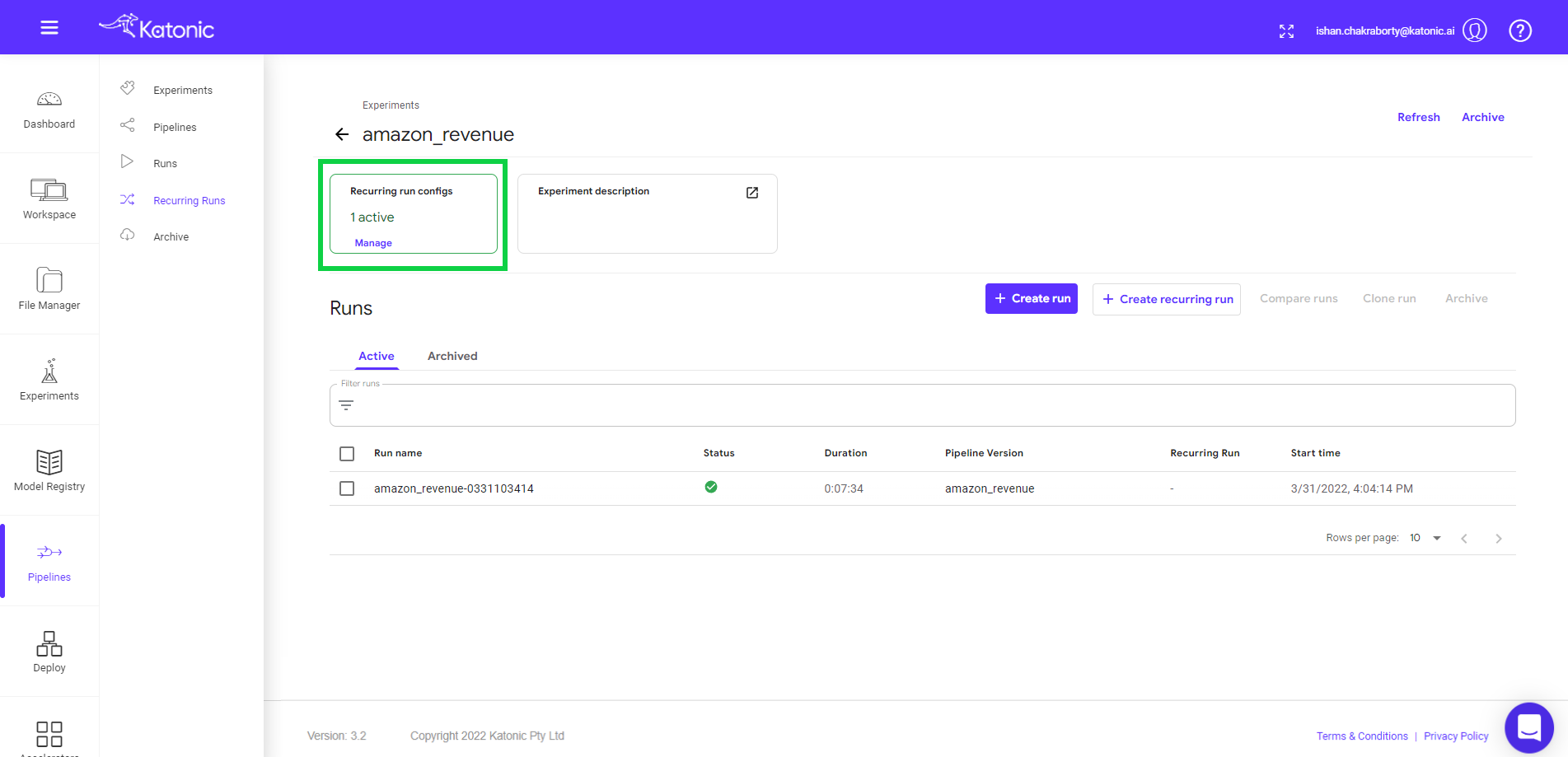
- Click on manage to enable or disable the scheduler.
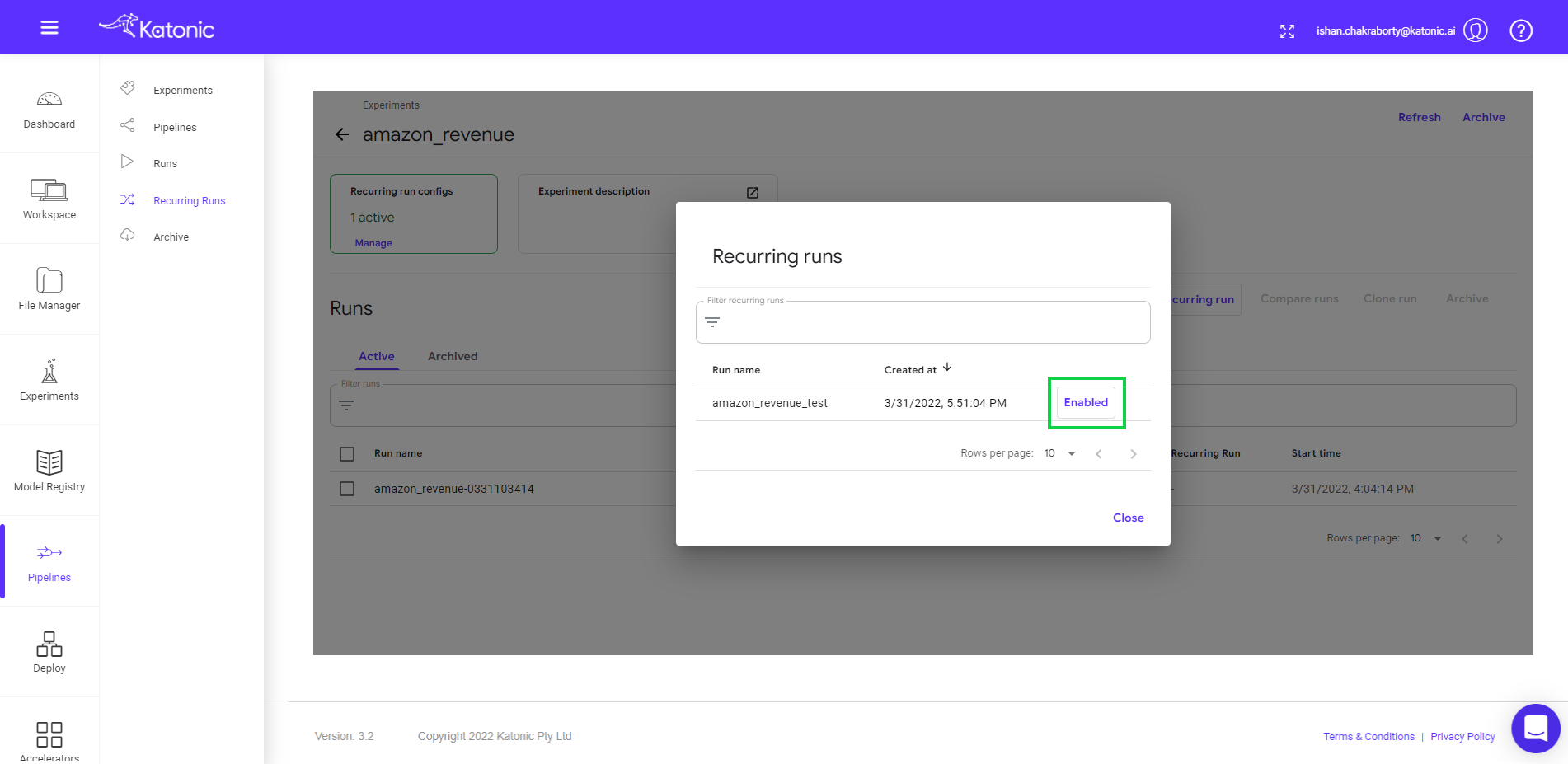
- Click on run to check the schedule configurations.