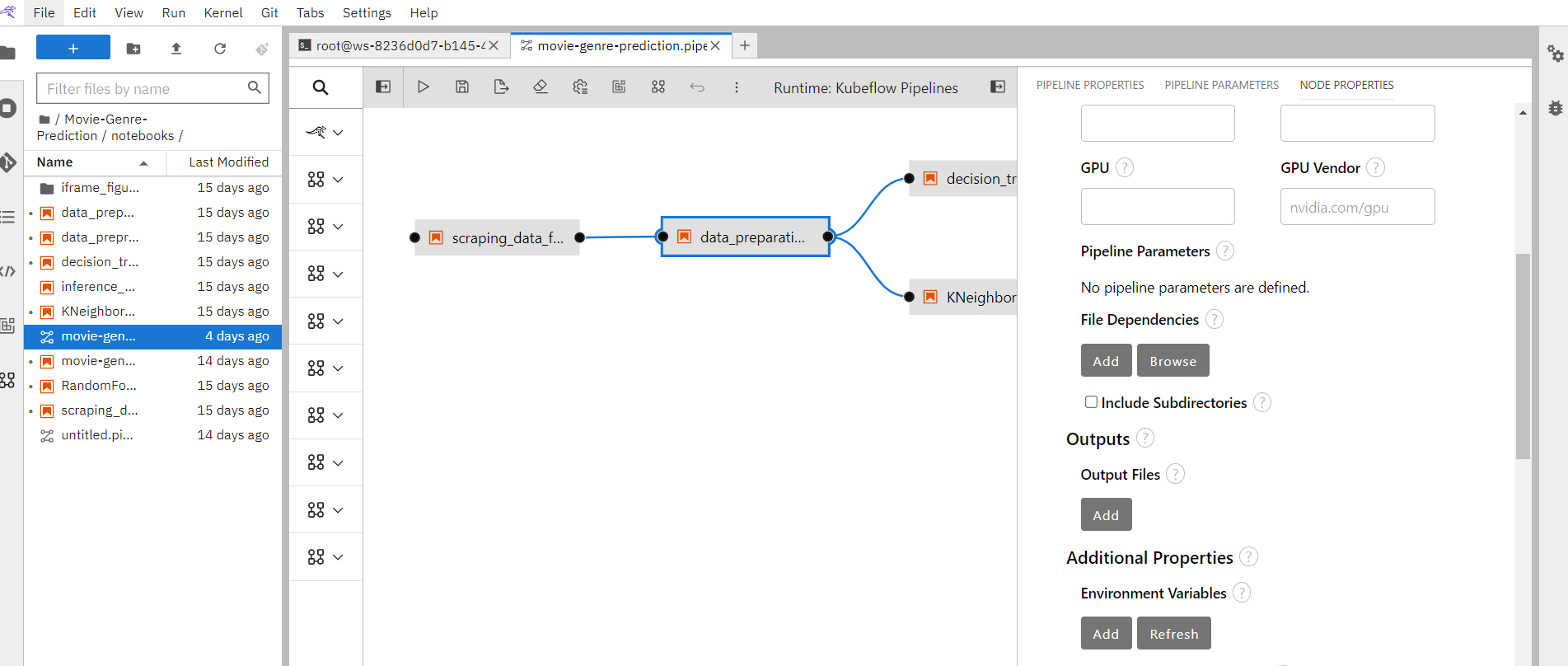
Converting a Notebook to Pipeline.
Before deploying a model to production, we will structure our notebooks containing all the experimentation into a pipeline. Pipelines are necessary as they will help to fully automate all the machine learning life cycle in the production environment. For this purpose, we'll use Katonic Studio.
To simplify the execution process and data science lifecycle, it is recommended that you break the complete experimentation into smaller steps or notebooks as shown.
So just go to the workspace, drag the notebooks and place them in the order of their execution. Attach notebooks to each other defining the dependencies.
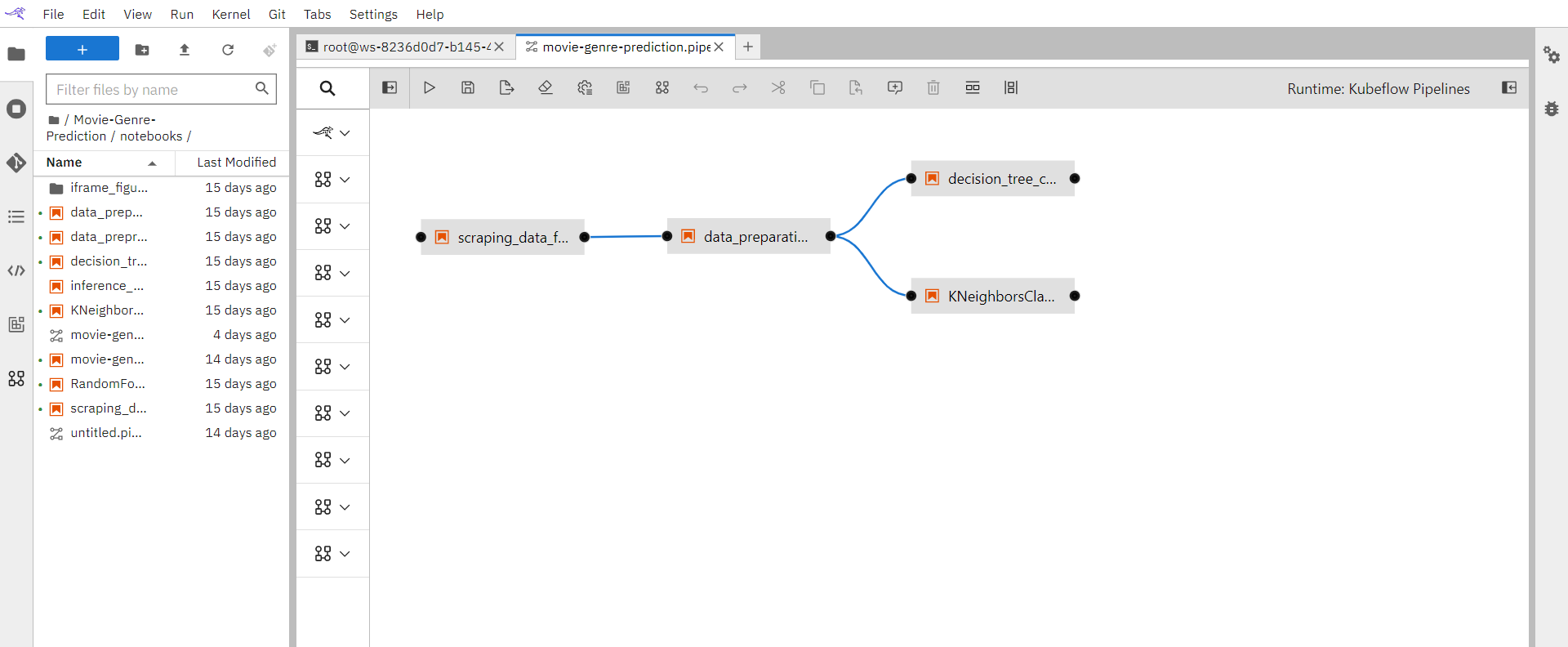
Set the properties for each notebook, to run it into respective environment.