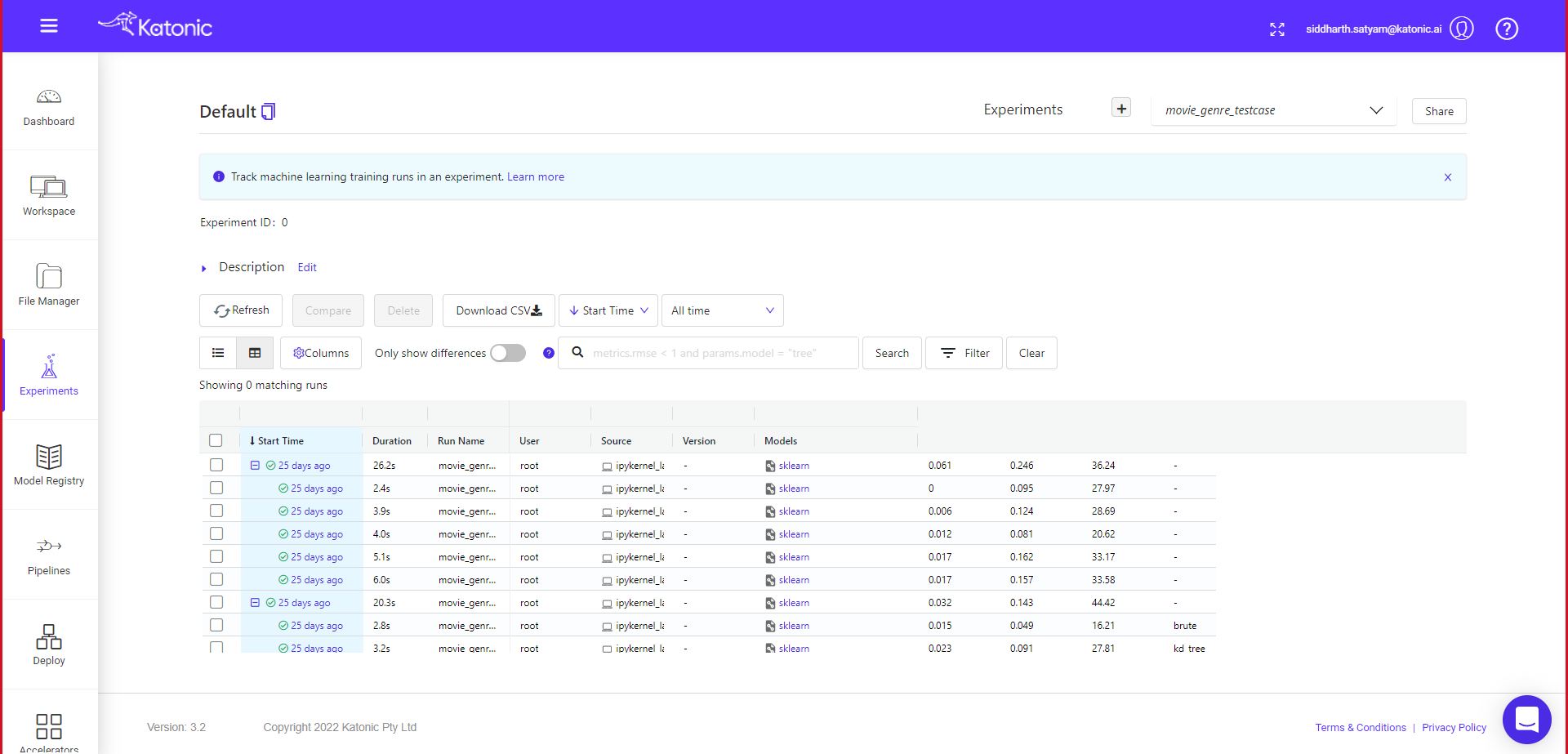
Experiments
Katonic Platform provides a central place to organize your ML experimentation. With the Katonic SDK you can log and display metrics, parameters, images and other ML metadata. In the Experiment Interface you can Search, group and compare runs with no extra effort. You can see and debug experiments live as they are running and query experiment metadata programmatically.
Creating experiments
Experiments in Katonic essentially allows you to group your models and any relevant metrics. For example, you can compare models that you’ve built in TensorFlow and in PyTorch and name this experiment something like pytorch_tensorflow. In the context of anomaly detection, you can create an experiment called model_prototyping and group all of the models that you want to test by running the training pipelines after setting model_prototyping as the experiment name. As you’ll see shortly, grouping model training sessions by experiment can really help organize your workspace because you’ll get a clear idea of the context behind trained models.
Model and metric logging
Katonic SDK allows you to save a model in a modularized form and log all of the metrics related to the model run. A model run can be thought of as the model training, testing, and validation pipeline. It is possible for you to train, evaluate, and even validate your model, logging all of the metrics for each respective step in the whole process. allowing you to much more easily compare different hyperparameter setups all at once.
Comparing model metrics
Katonic Experiment interface also allows you to compare different models and their metrics all at once. And so, when performing validation to help tune a model’s hyperparameters, you can compare all of the selected metrics together in Katonic platform using its Experiment interface.
Running an Experiment using Katonic SDK and Katonic Platform Interface
This topic walks you through a simple example to help you get started with Experiments in Katonic platform.
Let's build a simple machine learning project, Diabetes prediction. The objective of the use case is to diagnostically predict whether or not a patient has diabetes based on certain diagnostic measurements included in the dataset.
## imports
from katonic.ml.classification import Classifier
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, roc_auc_score
## Load the Data set
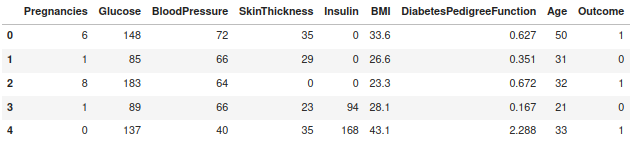
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/diabetes.csv')
df.head()
x = df.drop(columns=['Outcome'], axis=1)
y = df['Outcome']
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=.20,random_state=98)
## let's create experiment.
exp_name = 'diabetes_prediction_classifier'
# Initiate the classifier instance
clf = Classifier(X_train,X_test,y_train,y_test, exp_name)
exp_id = clf.id
print("experiment name : ",clf.name)
print("experiment location : ",clf.location)
print("experiment id : ",clf.id)
print("experiment status : ",clf.stage)
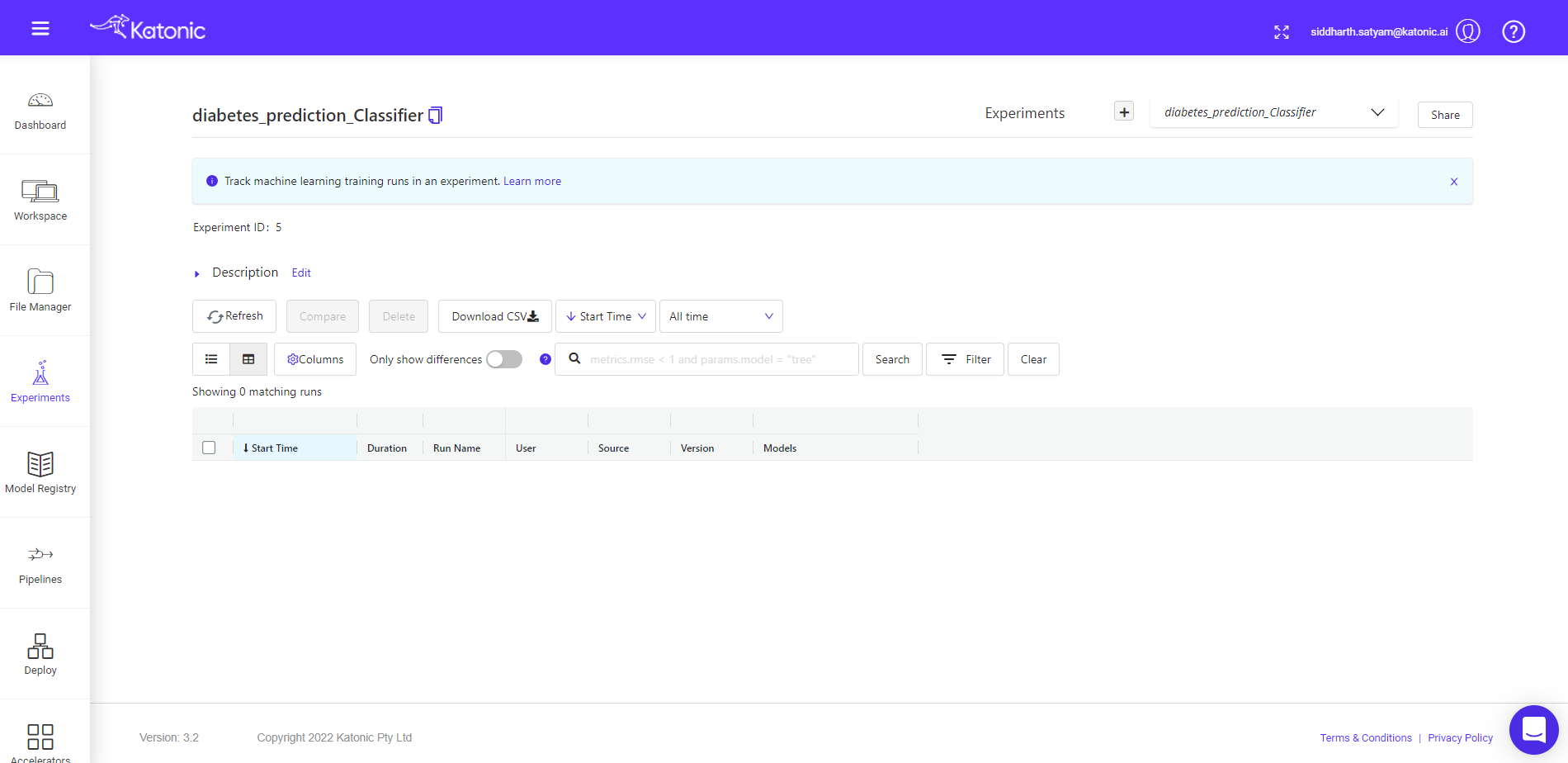
Now you can see an experiment of diabetes_prediction has been created. You can also see that experiment in the user interface.
Note: You can see the experiment, you will notice there are no model runs yet. It is just an empty experiment; we will now start applying different models and compare them later. Let's train and log some models
## Logistic regression
clf.LogisticRegression()
## Decision TreeClassifier
clf.DecisionTreeClassifier(max_depth=8, criterion='gini', min_samples_split=3)
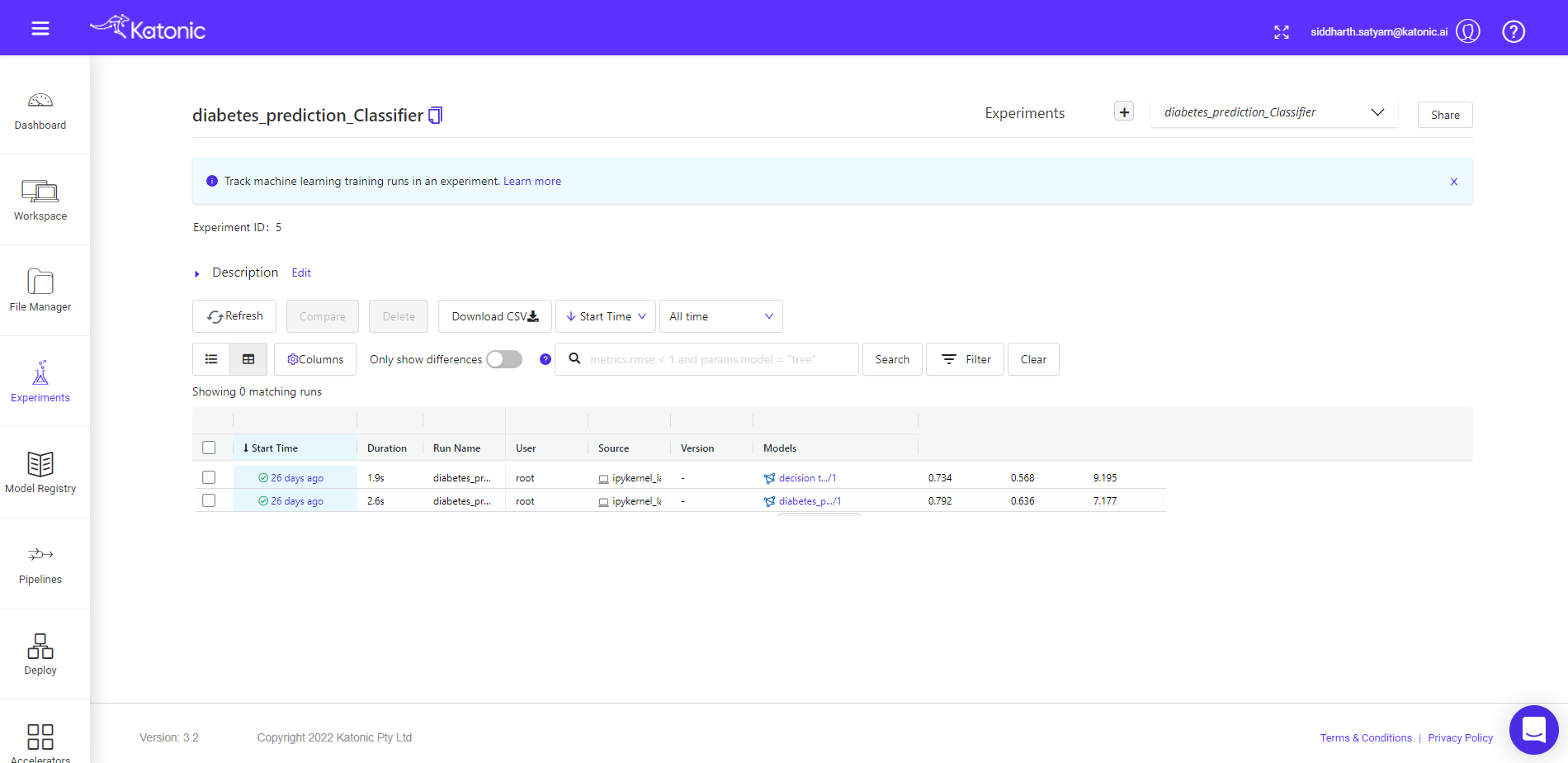
Up to this point we have trained two models, as these logs all the necessary metrics implicitly, you don’t have to worry about logging metrics explicitly.
Here you can see, the two models have been logged with the necessary metrics. You can further investigate the model run by clicking any of their corresponding start time. Once you click that, you can see the following window,
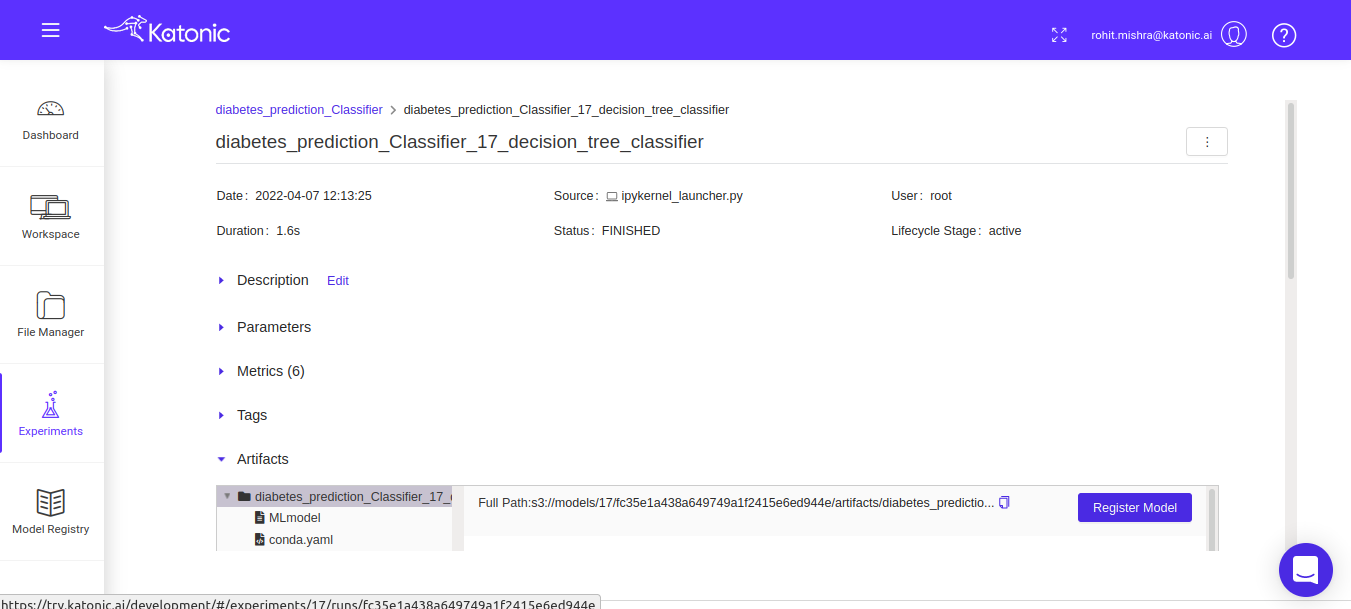
Here you can see the various details corresponding to given model run, the details of parameters used in the models, metrics tracked while training/testing model, associated artefacts and full path for the model registry where the serialized file of model is saved.
Let's come back to the previous window and compare both runs.
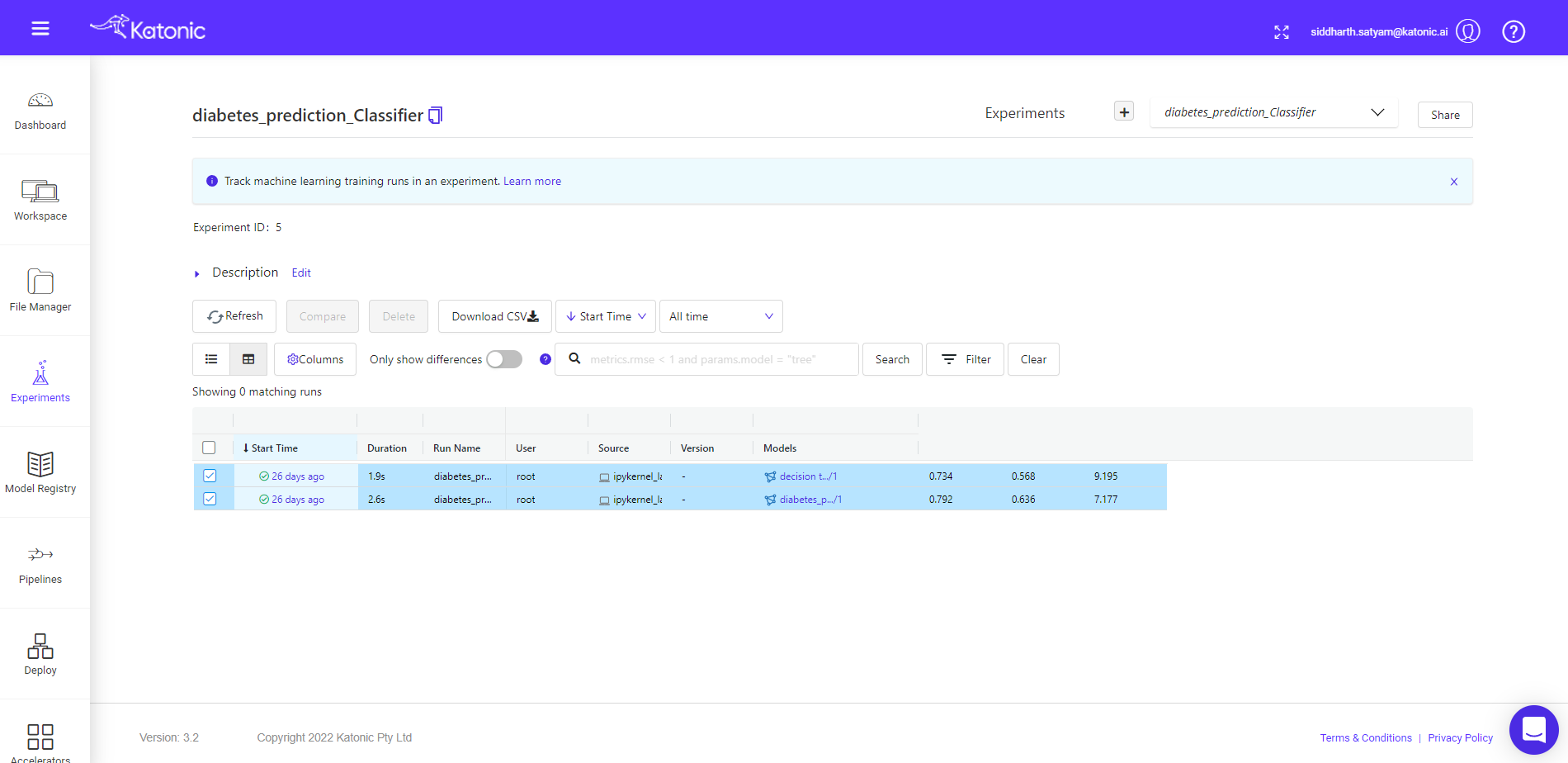
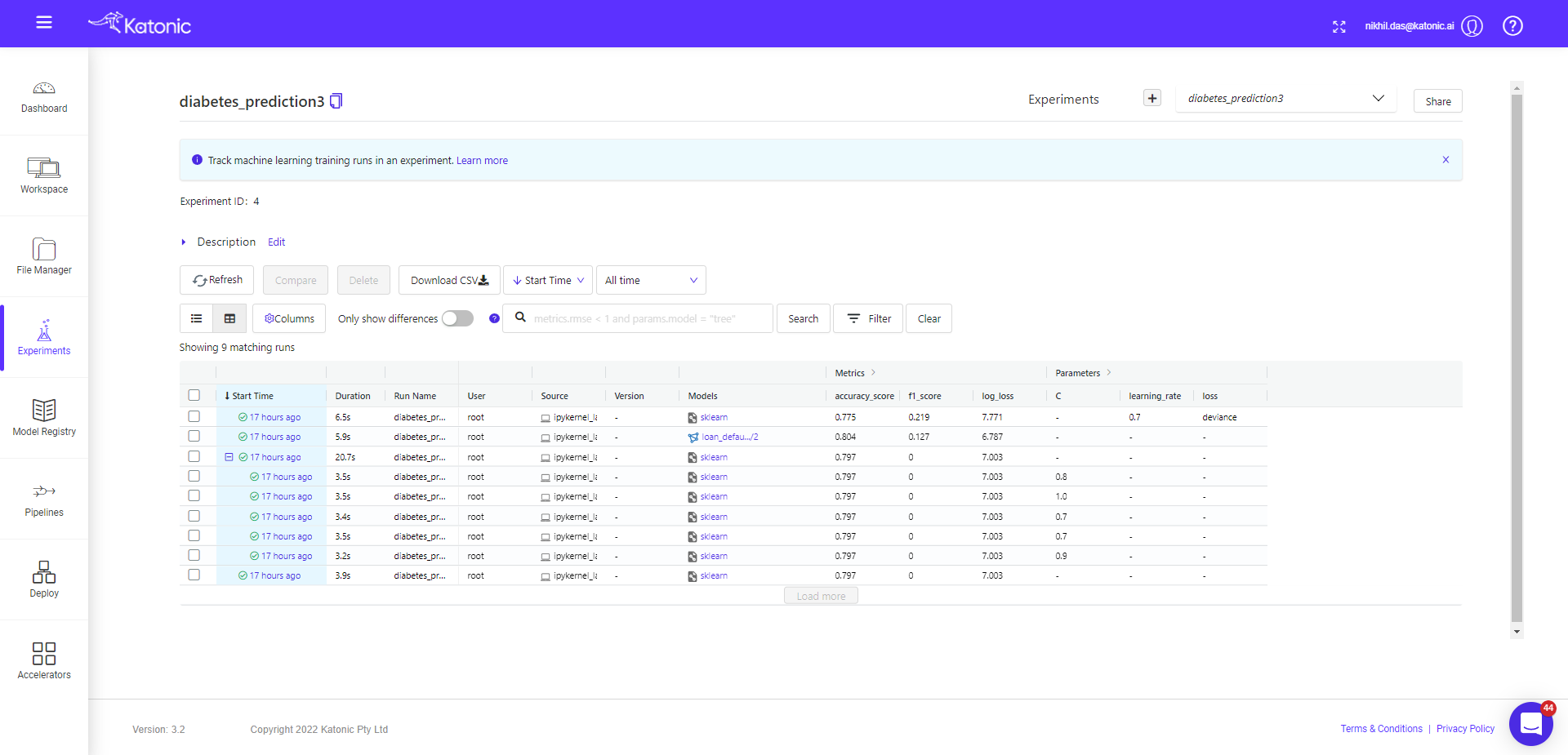
You can compare different model runs in the given experiment window.
First select the run, you want to compare, then click on the compare button. You will be taken to new window, where you will find details about plots, parameters and metrics difference.
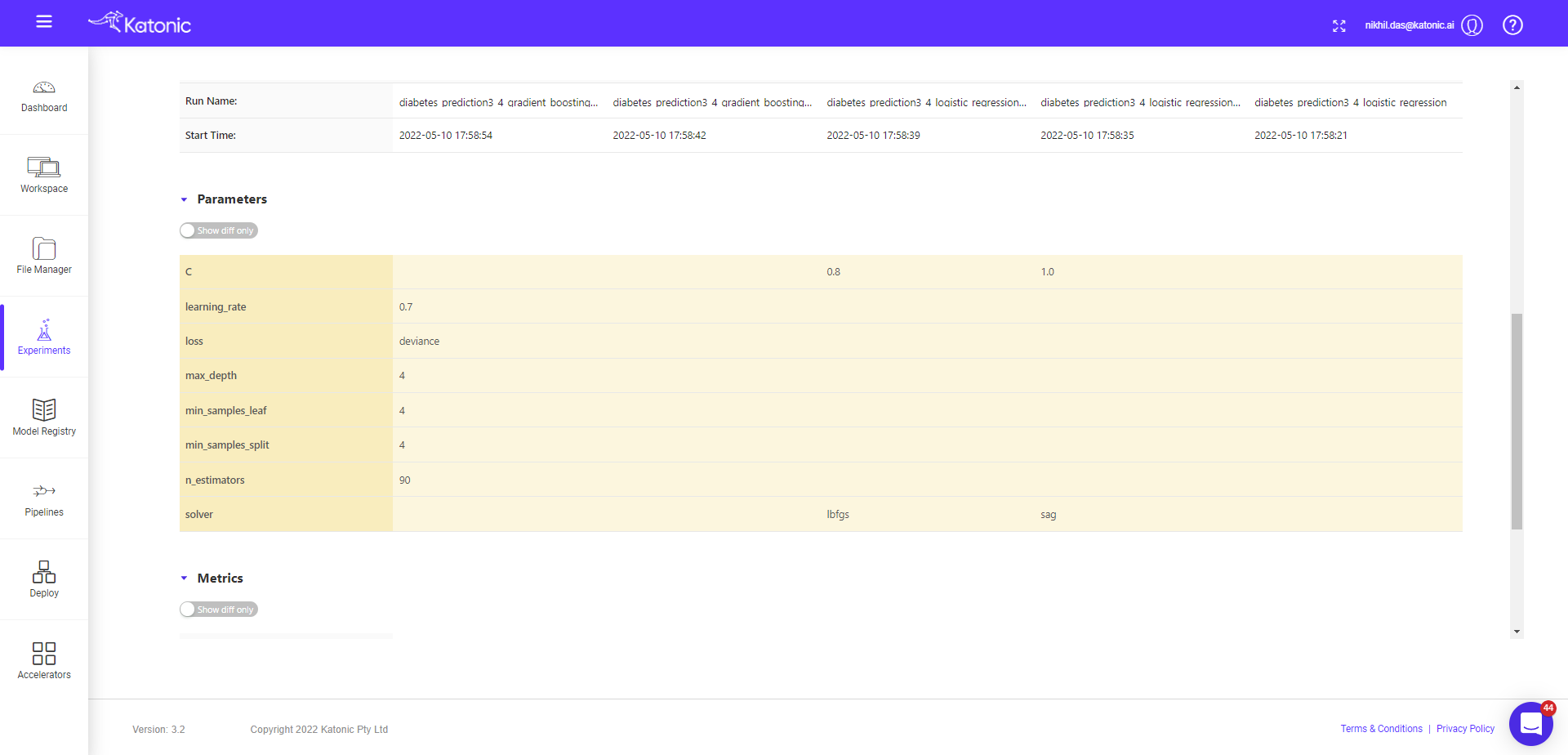
The given window page contains more details, so you need to scroll down to see further details available in the page, like run details, parameter details and metric details.
Now let's run a random forest model with hyperparameter tuning and compare all child run with parameters select by tuning algorithm.
## define parameters space for searching best parameters
params = {
'n_estimators': {
'low': 80,
'high': 120,
'step': 10,
'type': 'int'
},
'criterion':{
'values': ['gini', 'entropy'],
'type': 'categorical'
},
'min_samples_split': {
'low': 2,
'high': 5,
'type': 'int'
},
'min_samples_leaf':{
'low': 1,
'high': 5,
'type': 'int'
}
}
## train, tune and log Random Forest model.
clf.RandomForestClassifier(is_tune=True,n_trials=5, params=params)
Now come back to Experiment interface, you will see the + sign in front of one of the start time(corresponds to parent run), once expand that + option you will see all the child runs.
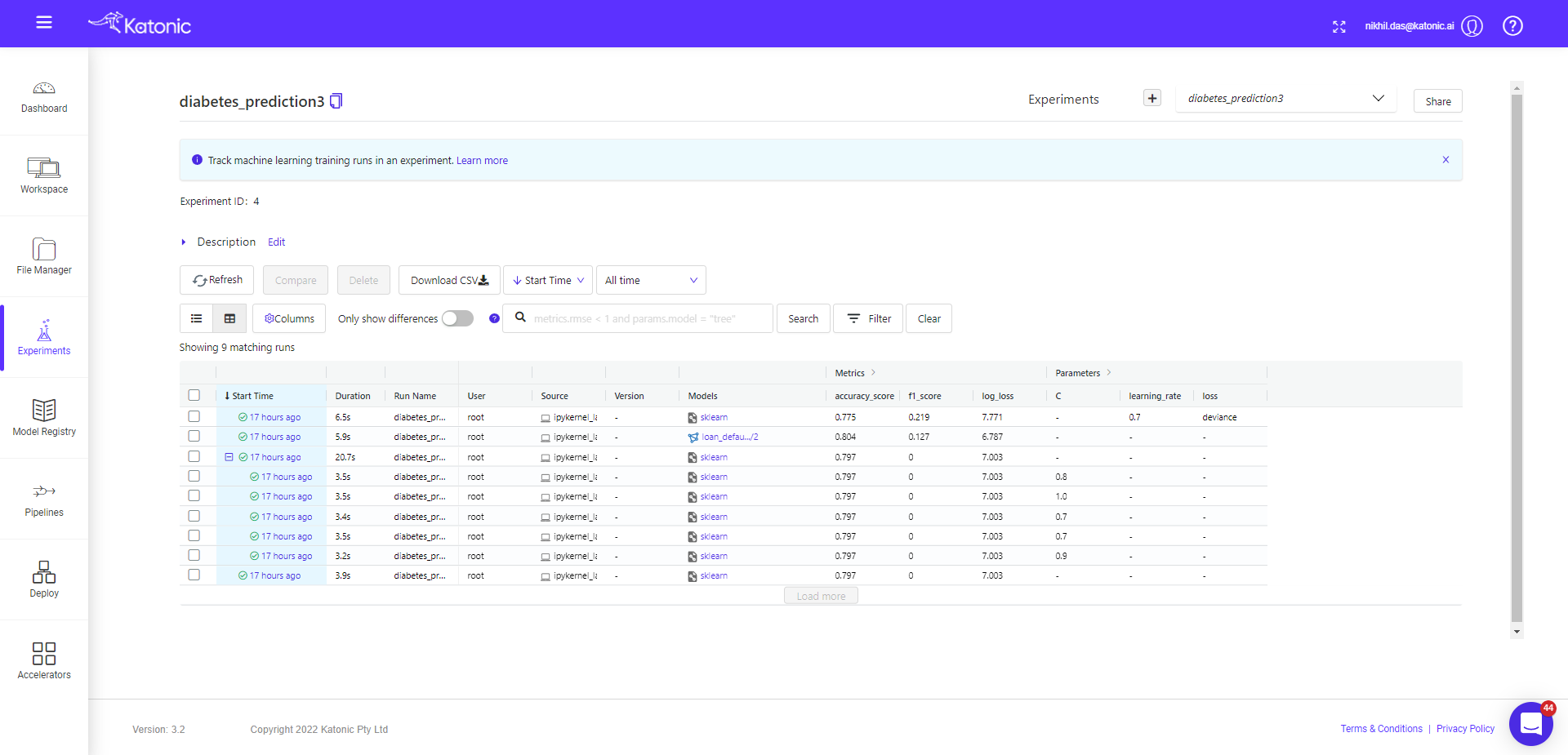
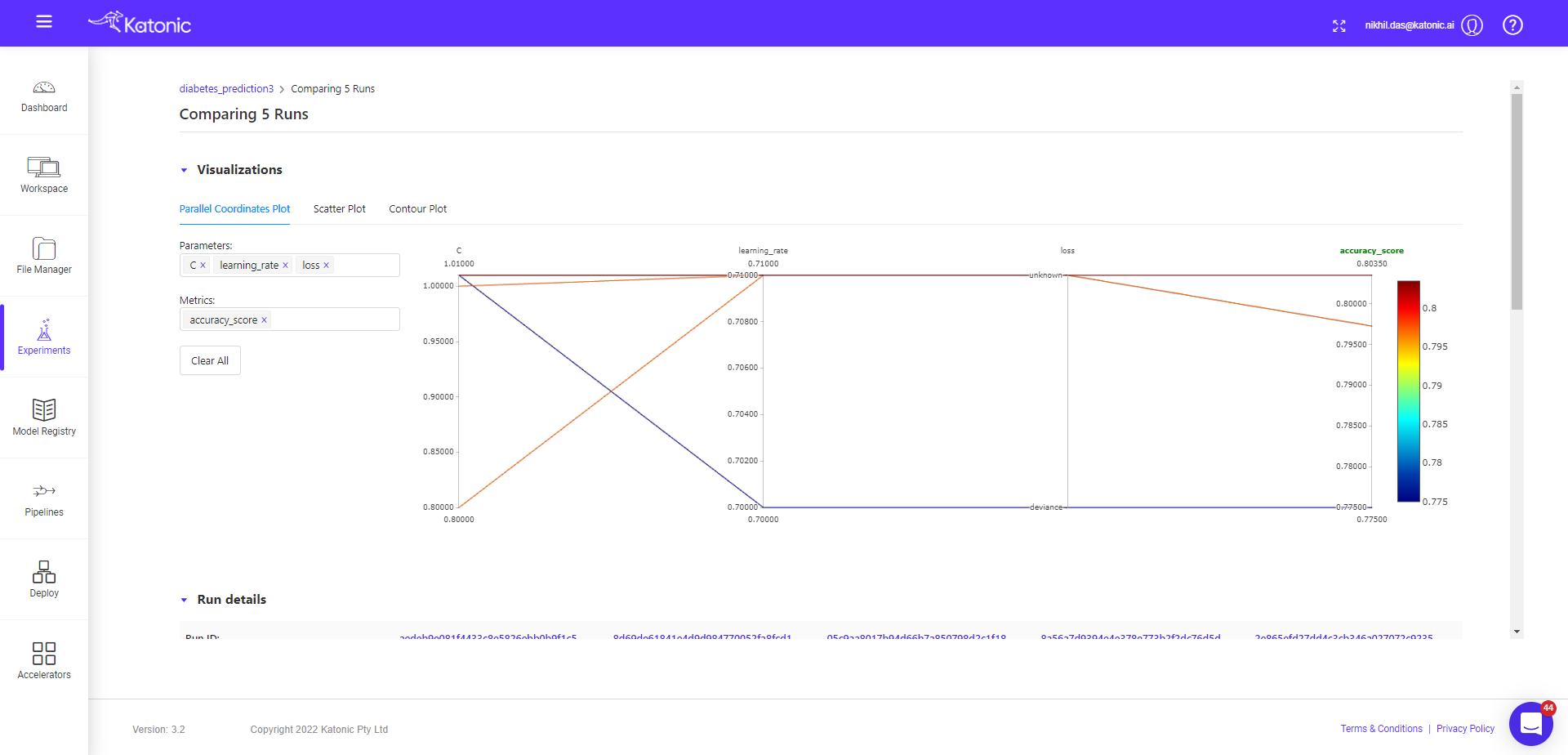
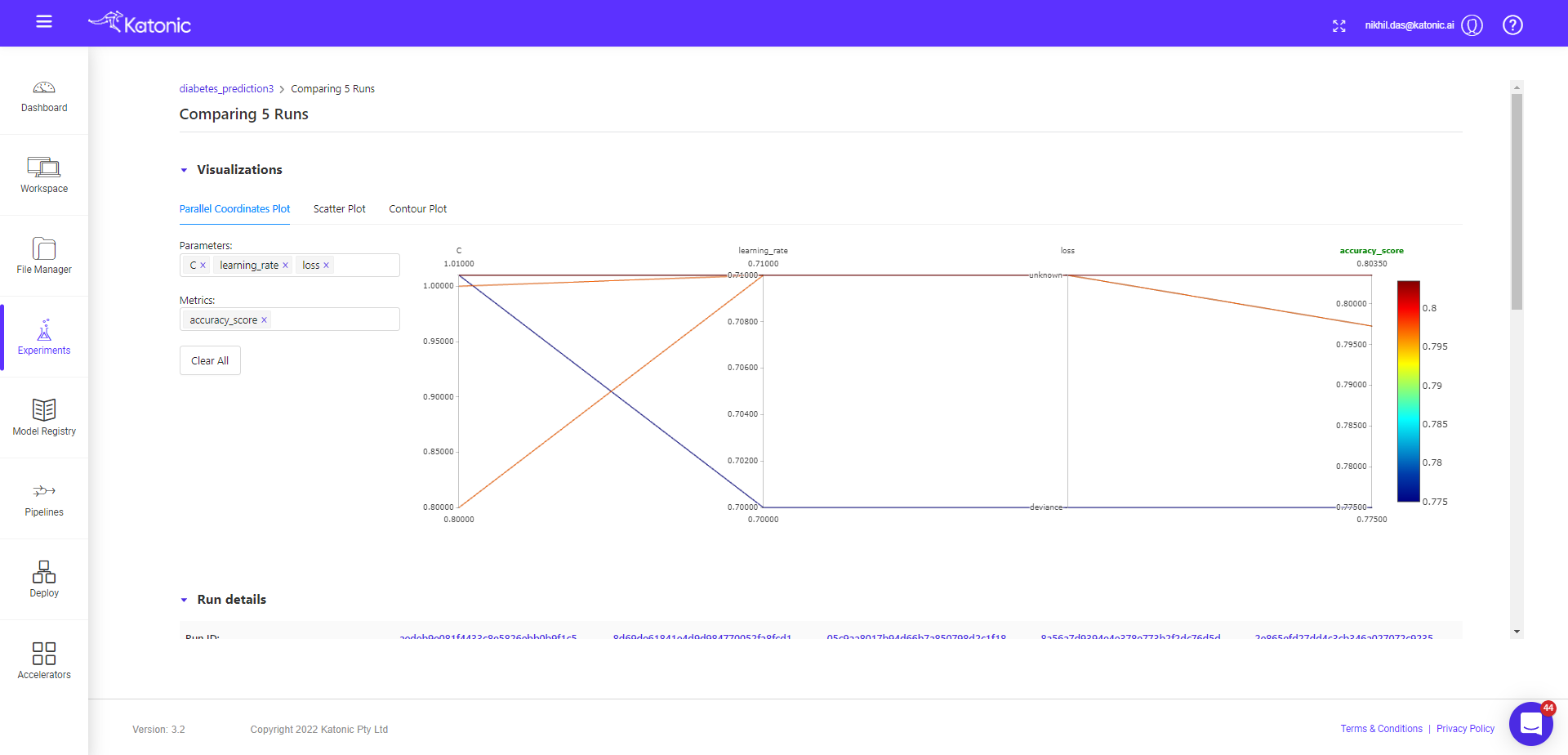
Now we will compare the child runs and see the parallel plots on how different params effecting the accuracy metrics (default).
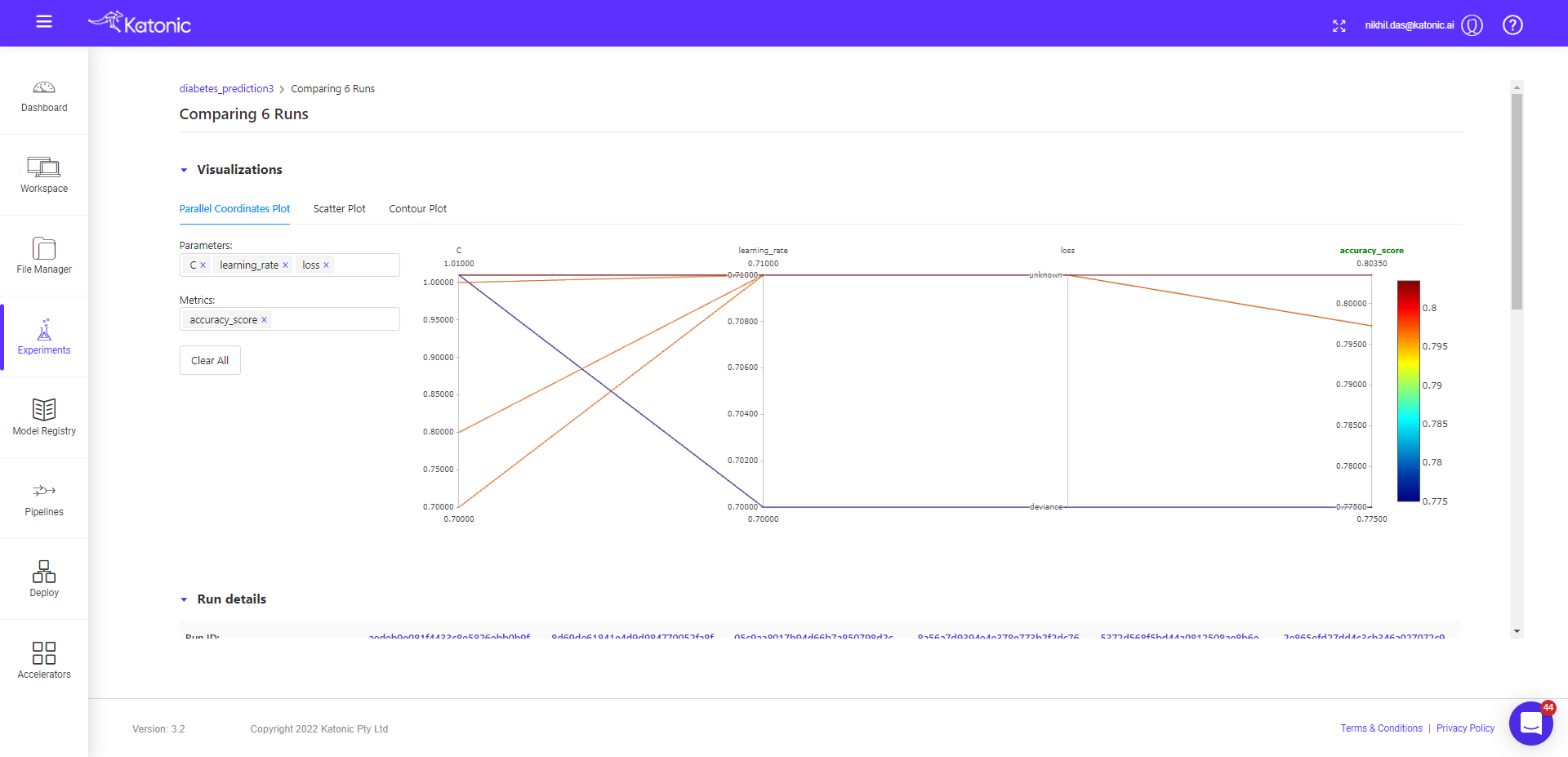
You can see, in the metrics tab accuracy is default variable, but you can choose other metrics also and visualize the effect of different params on the given metric value.
So up to here, you have been shown
● How to create experiments through SDK and interact with user interface.
● How to train and log models.
● How to compare runs of two different models.
● How to visualize and compare runs of hyperparameter tuned model.
● To train and log other models see documentation of Katonic SDK.
● To know how to register model, create new versions and transition model to different stages see our Model Registry Documentation.