Create Pipeline Using Custom Components
Overview
Katonic custom components are pre-built components based on low-code no-code architecture. The components help you built a full end-to-end pipeline without writing a single line of code.
The components can be dragged and dropped into to pipeline editor and can be run later.
To build the pipeline one component(Input Config) needs to be the 1st element in the pipeline that takes necessary parameters from the user, then
all these parameters are traversed throughout the entire pipeline.
Other components are required some specific parameters to run them and the input-config parameters taken from the previous component using a dropdown menu.
The components take column names to perform transformation and create new columns and concatenate it to the dataframe. Each component performs a filtering operation on the data to determine which columns are suitable for the respective transformation. If a component finds no suitable column to perform the given transformation an exception will be raised and the pipeline will stop.
Input Config
This is the most important component in the pipeline building process, it needs to be the first component in all the pipelines. It takes some necessary parameters as input that is necessary for the pipeline to run.
- DATA PATH: The path to the data file that will be used in the training pipeline(format: csv/pkl)
- IS TRAINING: A flag to know if the pipeline is for training or testing, for training it needs to be True, and for testing it needs to be False(default: True).
- TARGET COLUMN: The target/label/class column name for the use-case to prevent any unwanted preprocessing on the column
- ID COLUMNS: The id column name to track and merge the data, has to be unique(Create one unique id column if doesn't exist in the data)
- STORAGE BUCKET: Katonic file manager bucket name.
- FOLDER NAME: Name of the pipeline parent folder(When IS_TRAINING=False, make sure to pass the folder name with timestamp created at the time of training)
- ACCESS KEY: Access key of katonic file manager bucket
- SECRET KEY: Secret key of katonic file manager bucket

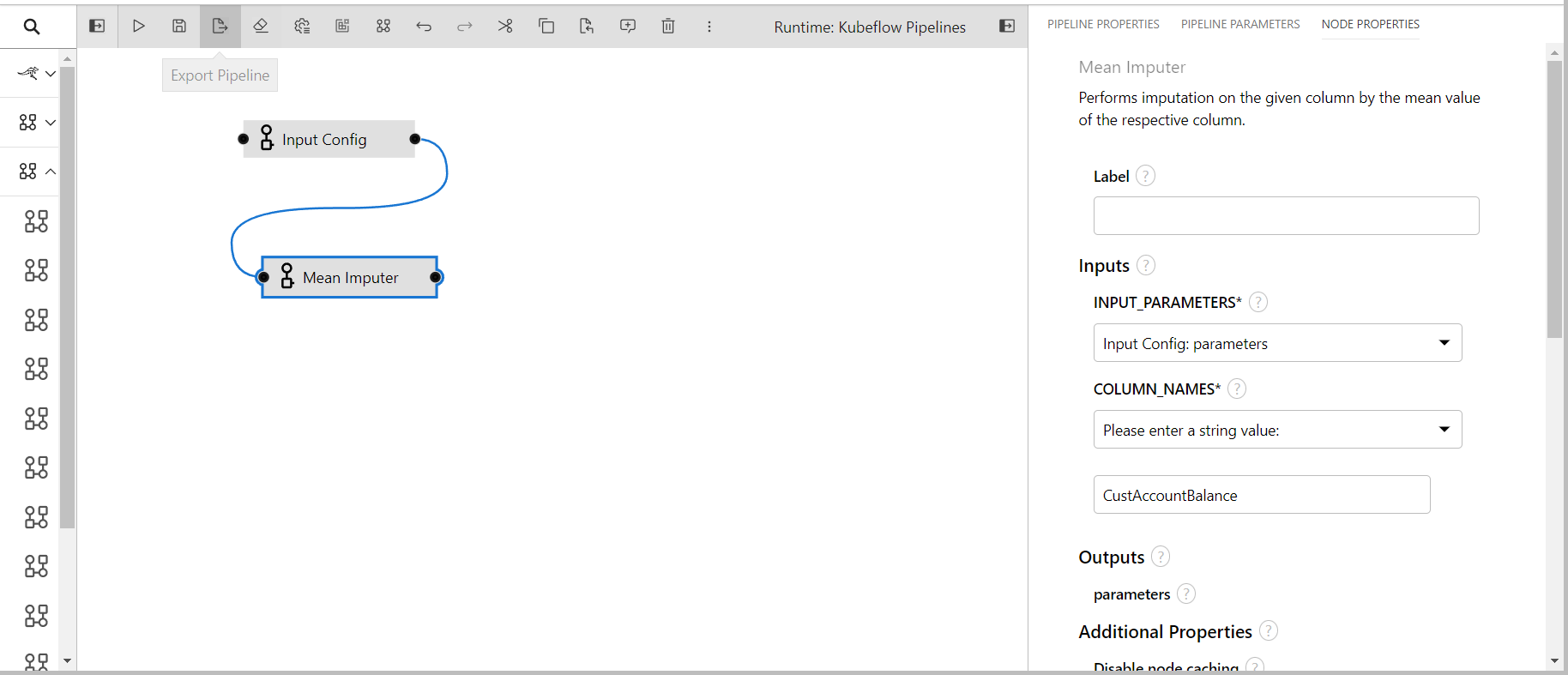
Mean Imputer
This component performs mean imputation on the given columns of the data, the operation can be performed on numerical columns.
- INPUT_PARAMETERS: Take the input parameter configurations from the previous component.
- COLUMN_NAMES: Columns name to perform transformation(input: comma separated if multiple)
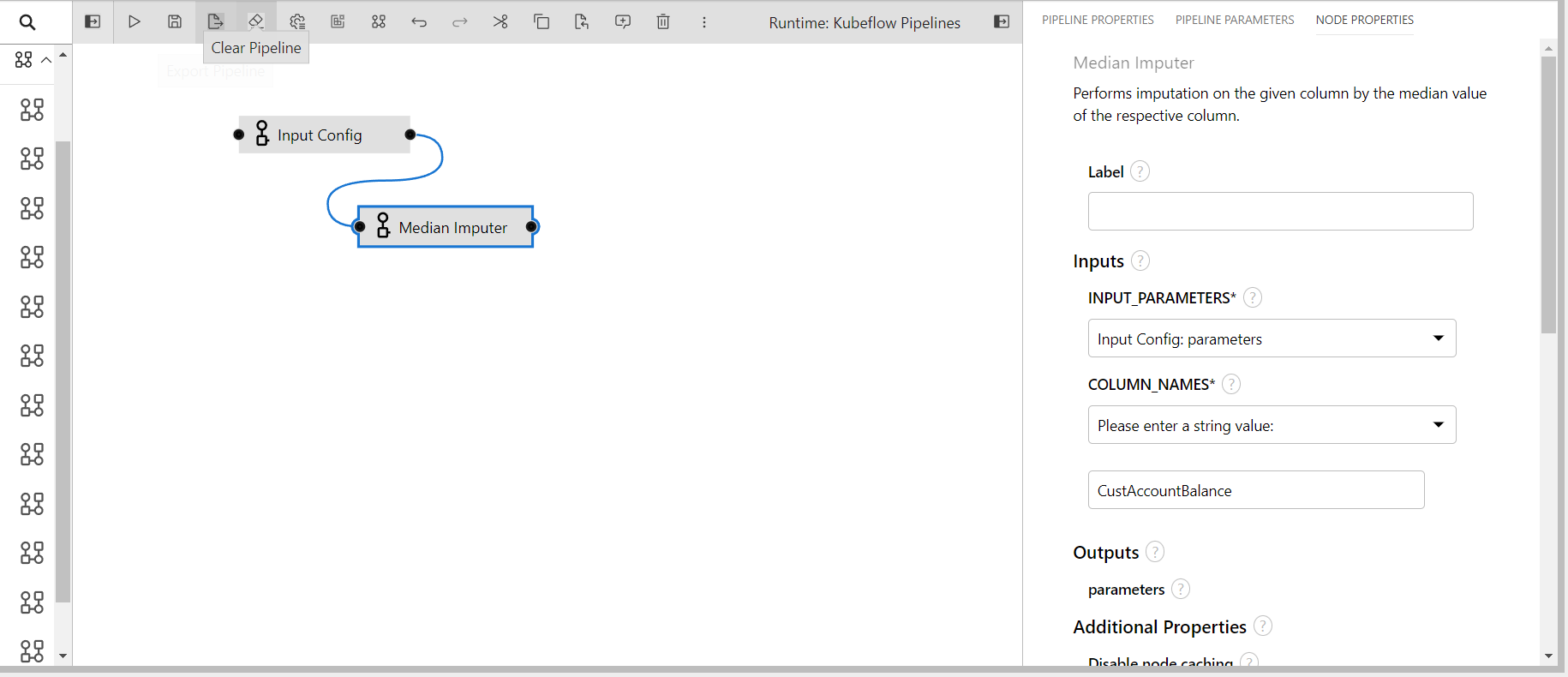
Median Imputer
This component performs median imputation on the given columns of the data, the operation can be performed on numerical columns.
- INPUT_PARAMETERS: Take the input parameter configurations from the previous component.
- COLUMN_NAMES: Columns name to perform transformation(input: comma separated if multiple)
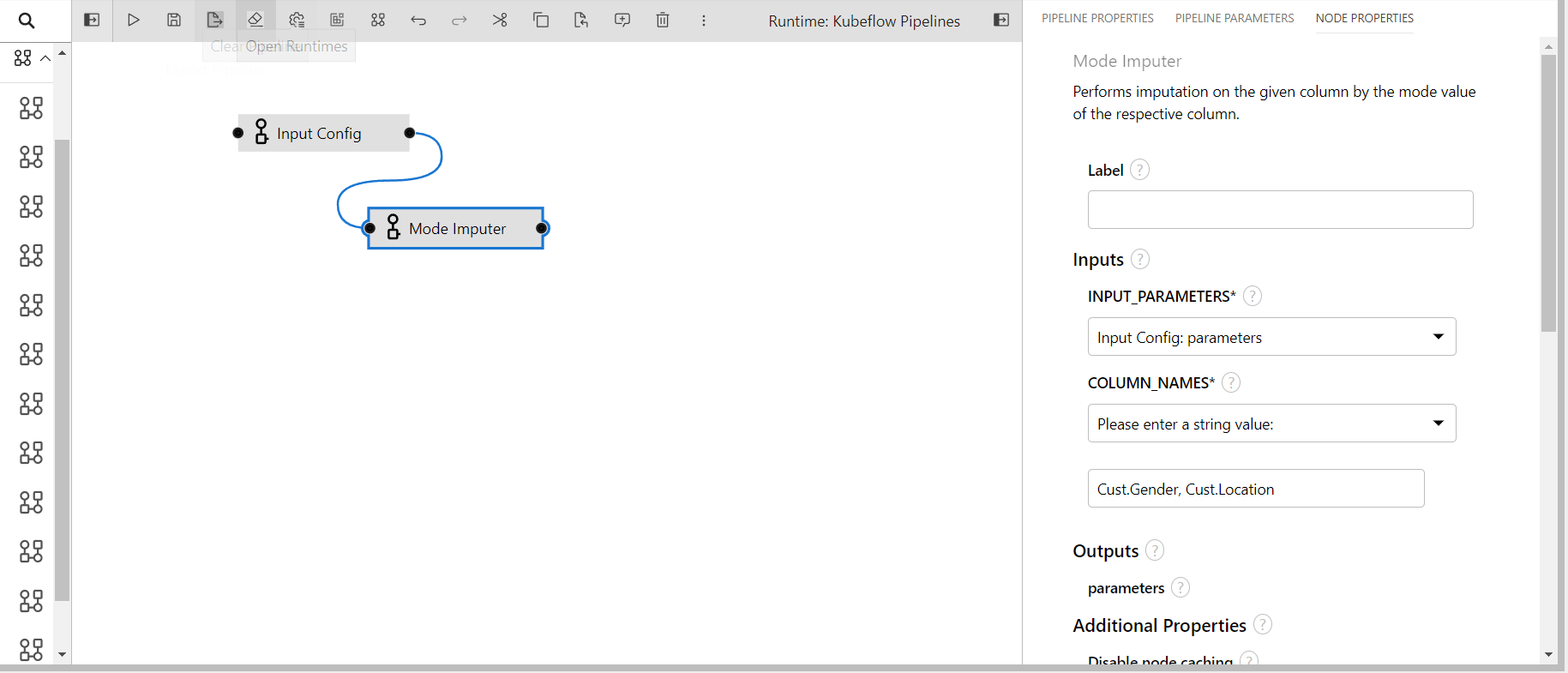
Mode Imputer
This component performs mode imputation on the given columns of the data, the operation can be performed on categorical columns(numeric/string).
- INPUT_PARAMETERS: Take the input parameter configurations from the previous component.
- COLUMN_NAMES: Columns name to perform transformation(input: comma separated if multiple)
New Category Imputer
This component imputers categorical columns by assigning a new category to the null on the given columns of the data, the operation can be performed on categorical columns.
- INPUT_PARAMETERS: Take the input parameter configurations from the previous component.
- COLUMN_NAMES: Columns name to perform transformation(input: comma separated if multiple)
- FILL_VALUE: The new value to fill the columns with(default: UNKNOWN)
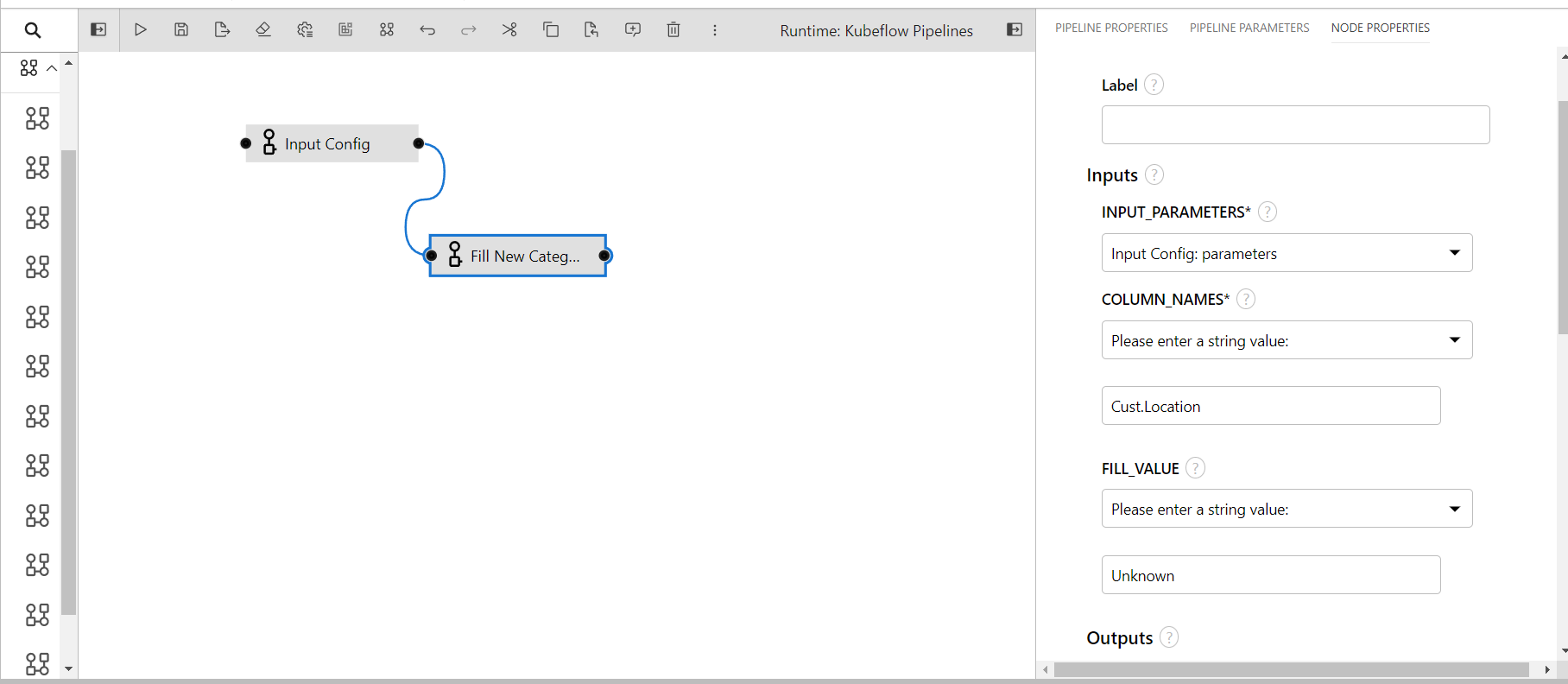
Backward Fill Imputation
This component performs backward fill imputation on the given columns of the data.
- INPUT_PARAMETERS: Take the input parameter configurations from the previous component.
- COLUMN_NAMES: Columns name to perform transformation(input: comma separated if multiple)
- SORT_COLUMNS: Columns to sort the data before performing backward fill imputation(input: comma separated if multiple)
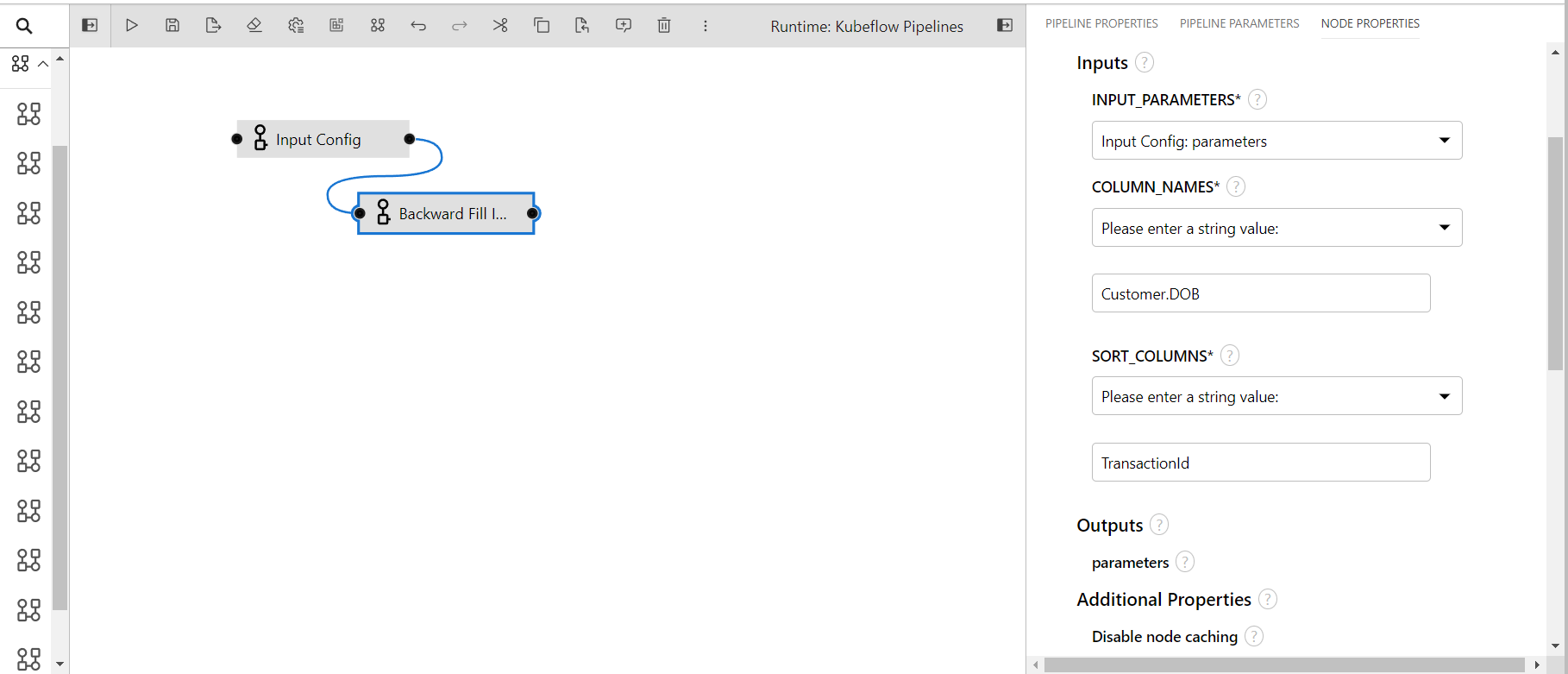
Forward Fill Imputation
This component performs forward fill imputation on the given columns of the data.
- INPUT_PARAMETERS: Take the input parameter configurations from the previous component.
- COLUMN_NAMES: Columns name to perform transformation(input: comma separated if multiple)
- SORT_COLUMNS: Columns to sort the data before performing backward fill imputation(input: comma separated if multiple)
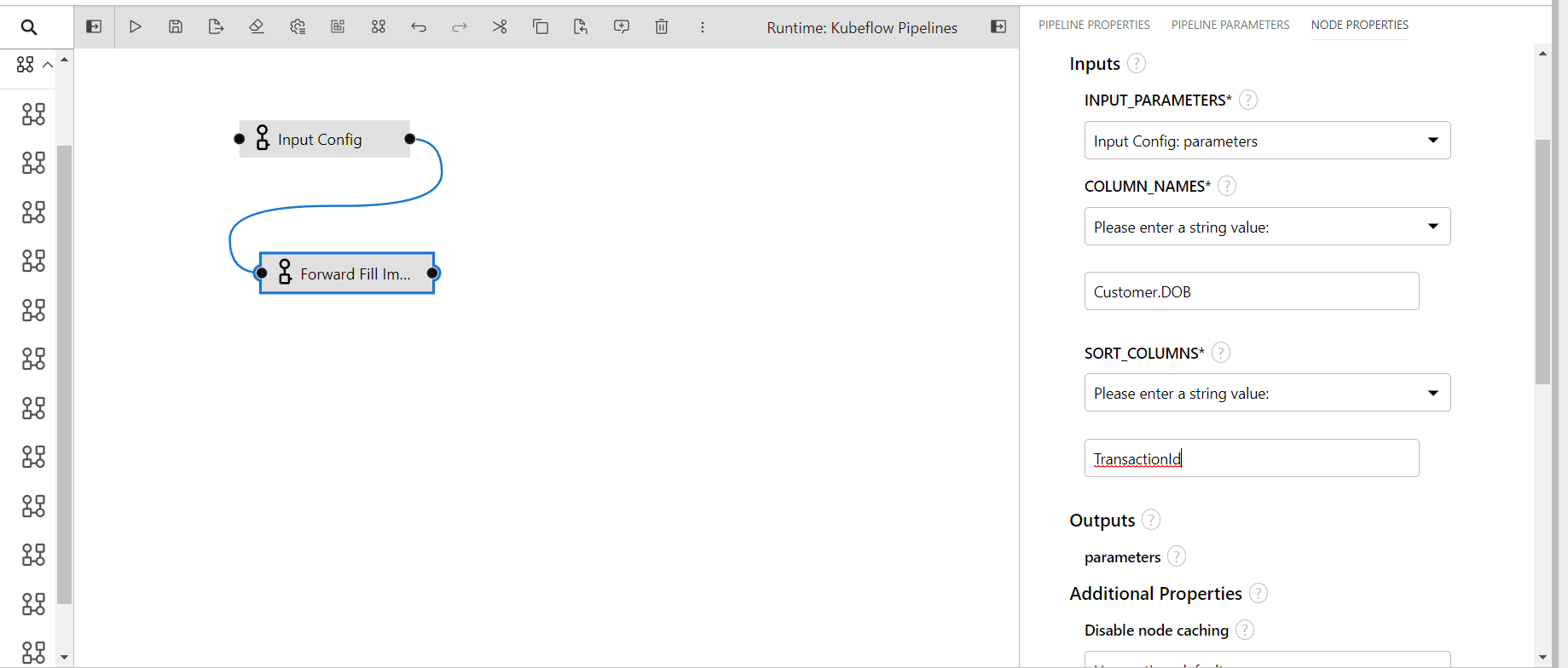
Fill With Zero Imputer
This component performs imputation by filling the null values with zero on the given columns of the data.
- INPUT_PARAMETERS: Take the input parameter configurations from the previous component.
- COLUMN_NAMES: Columns name to perform transformation(input: comma separated if multiple)
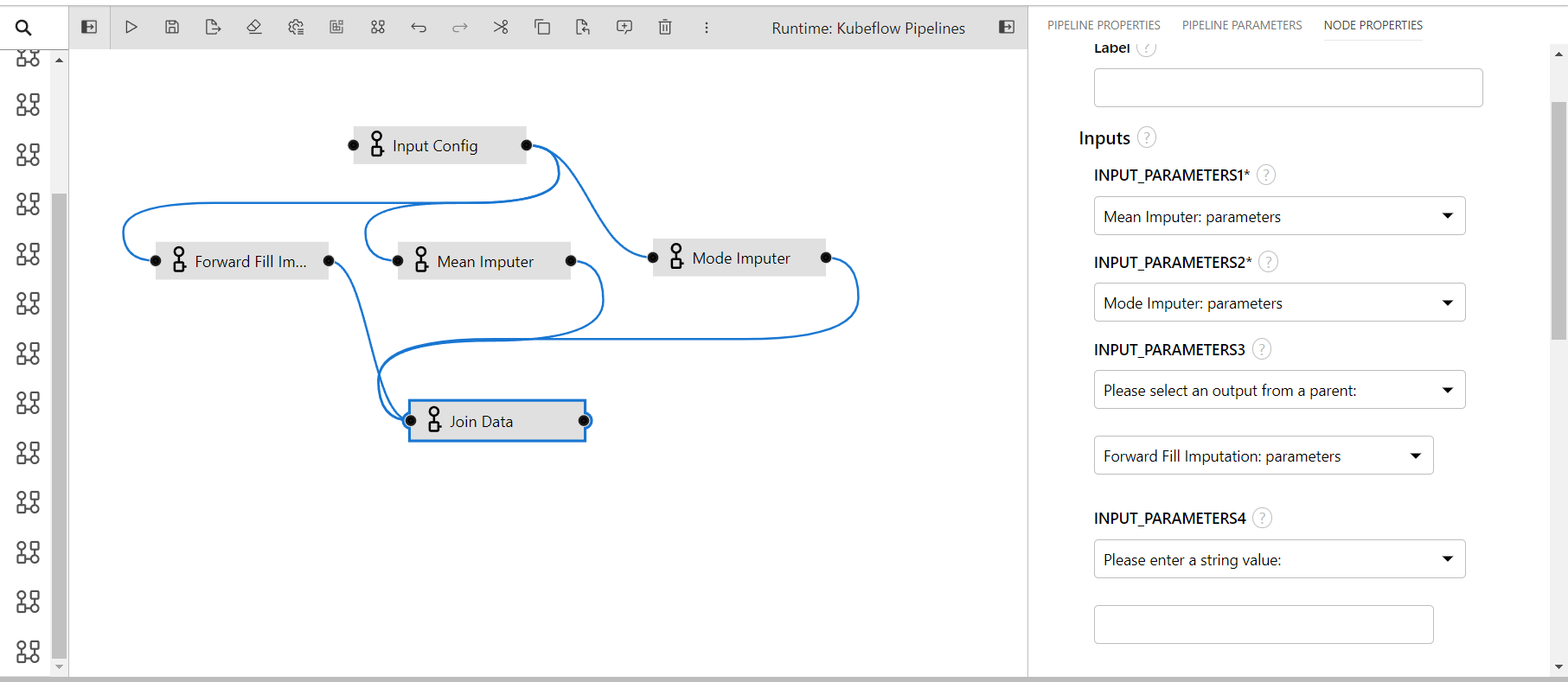
Join Data
There are times when you want to run several components parallelly and join the outputs of all components into a single data frame, at this time this component can be used. It can take up to 4 components of data and join them in a single data frame, to perform the operation all of the data needs to have one common unique id columns that will be taken as input in the input config component.
- INPUT_PARAMETERS1: The input config parameters taken from the previous component(required)
- INPUT_PARAMETERS2: The input config parameters taken from the previous component(required)
- INPUT_PARAMETERS3: The input config parameters taken from the previous component(optional)
- INPUT_PARAMETERS4: The input config parameters taken from the previous component(optional)
The component needs at least two inputs data to run the other two are optional those can be left empty.
To provide input inside the optional parameters you must change the Please enter a string value: to Please select an output from a parent
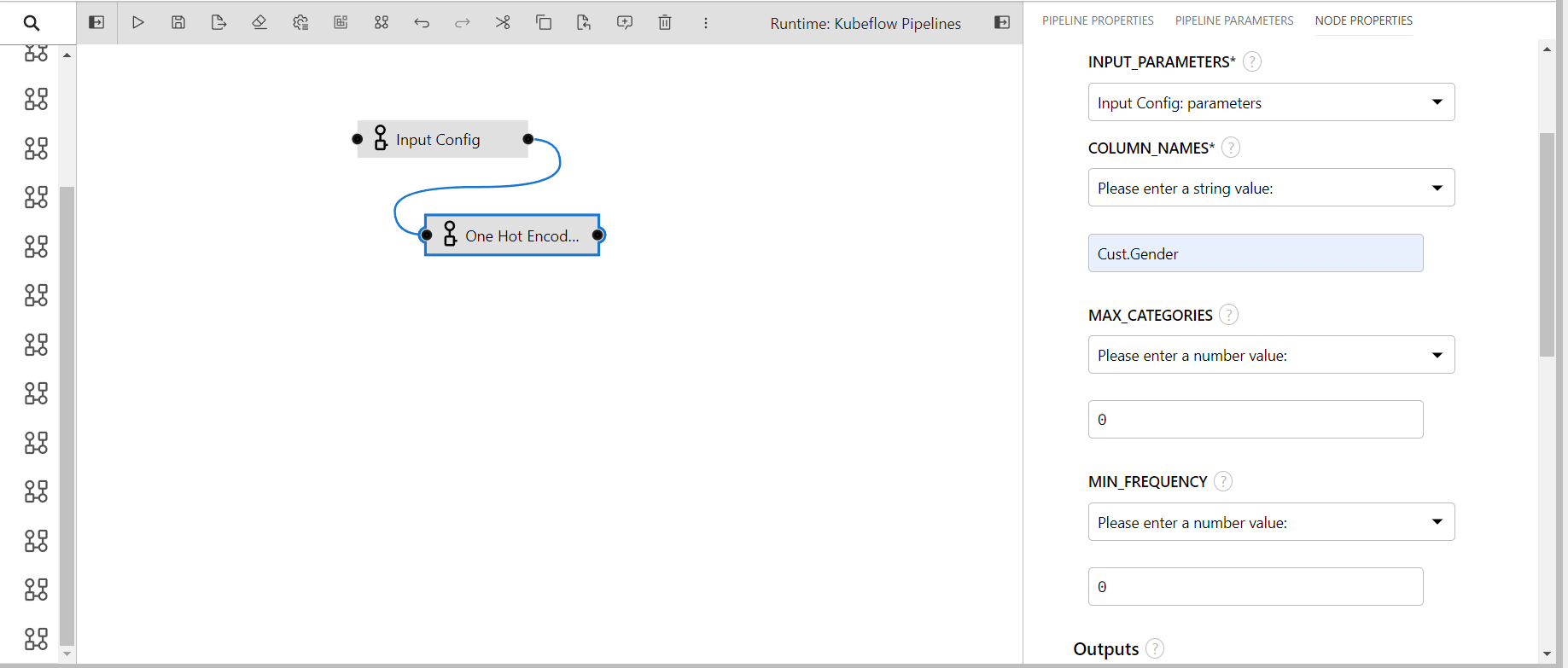
One Hot Encoder
The component performs one hot encoding on the given columns of the data.
- INPUT_PARAMETERS: Take the input parameter configurations from the previous component
- COLUMN_NAMES: Columns name to perform transformation(input: comma seperated if multiple)
- MAX_CATEGORIES: Specifies an upper limit to the number of output features for each input feature when considering infrequent categories
- MIN_FREQUENCY: Specifies the minimum frequency below which a category will be considered infrequent
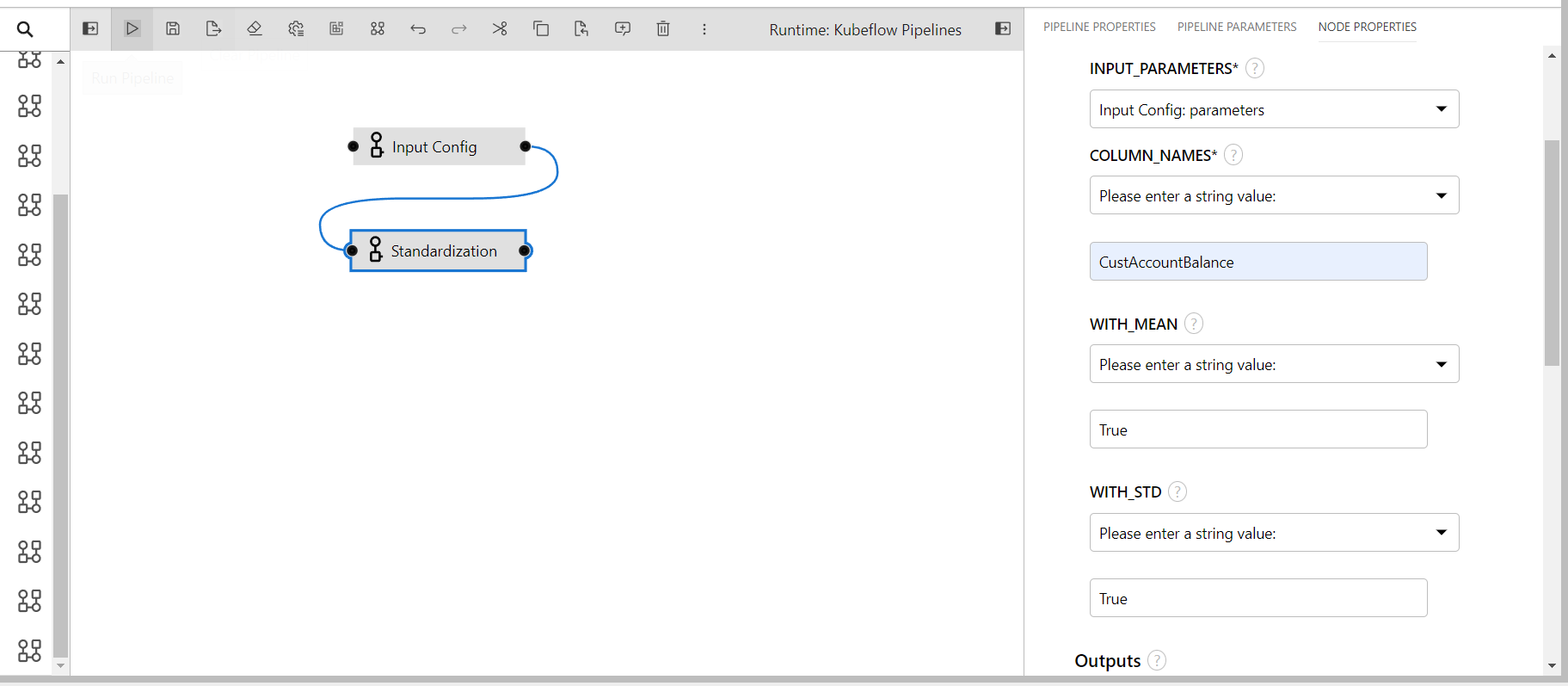
Standardization
The component scales the data of the given columns.
- INPUT_PARAMETERS: Take the input parameter configurations from the previous component
- COLUMN_NAMES: Columns name to perform transformation(input: comma separated if multiple)
- WITH_MEAN: If True, center the data before scaling
- WITH_STD: If True, scale the data to unit variance
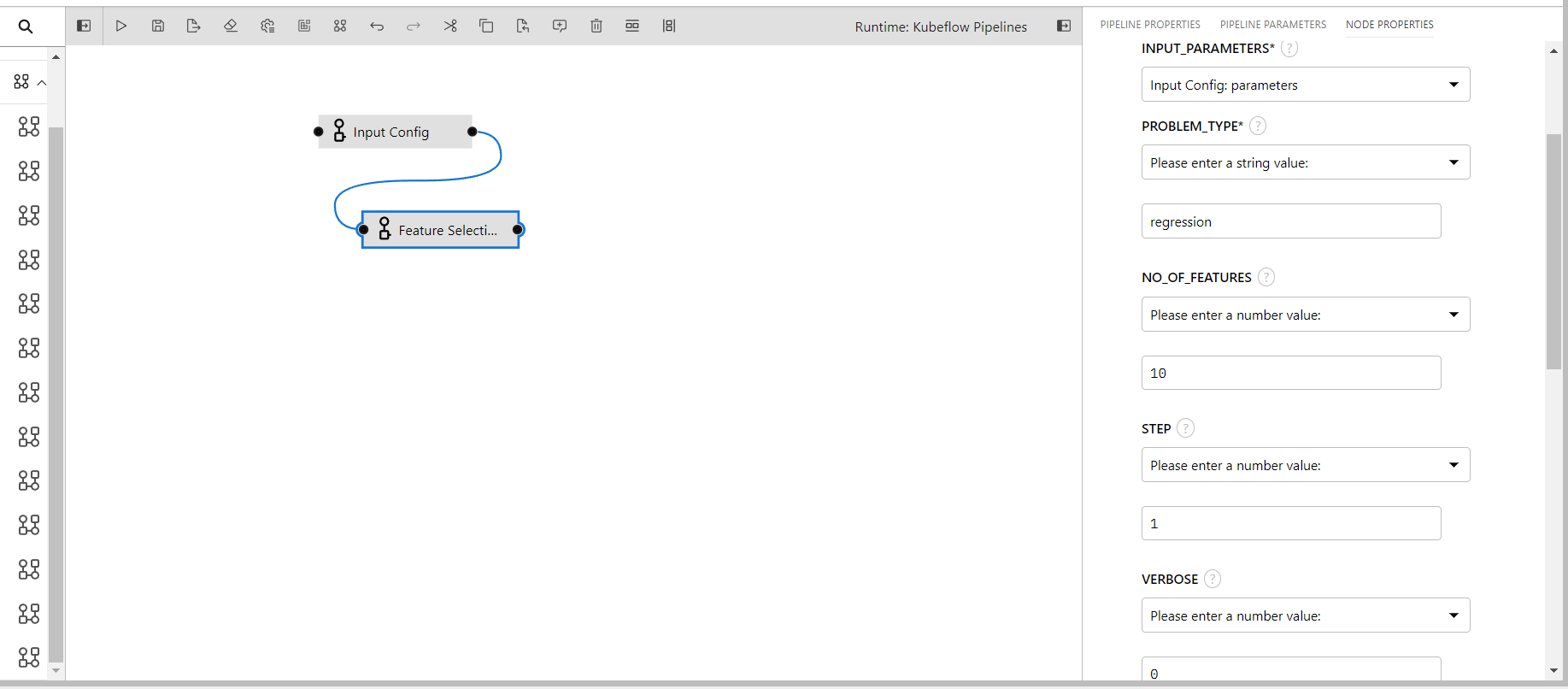
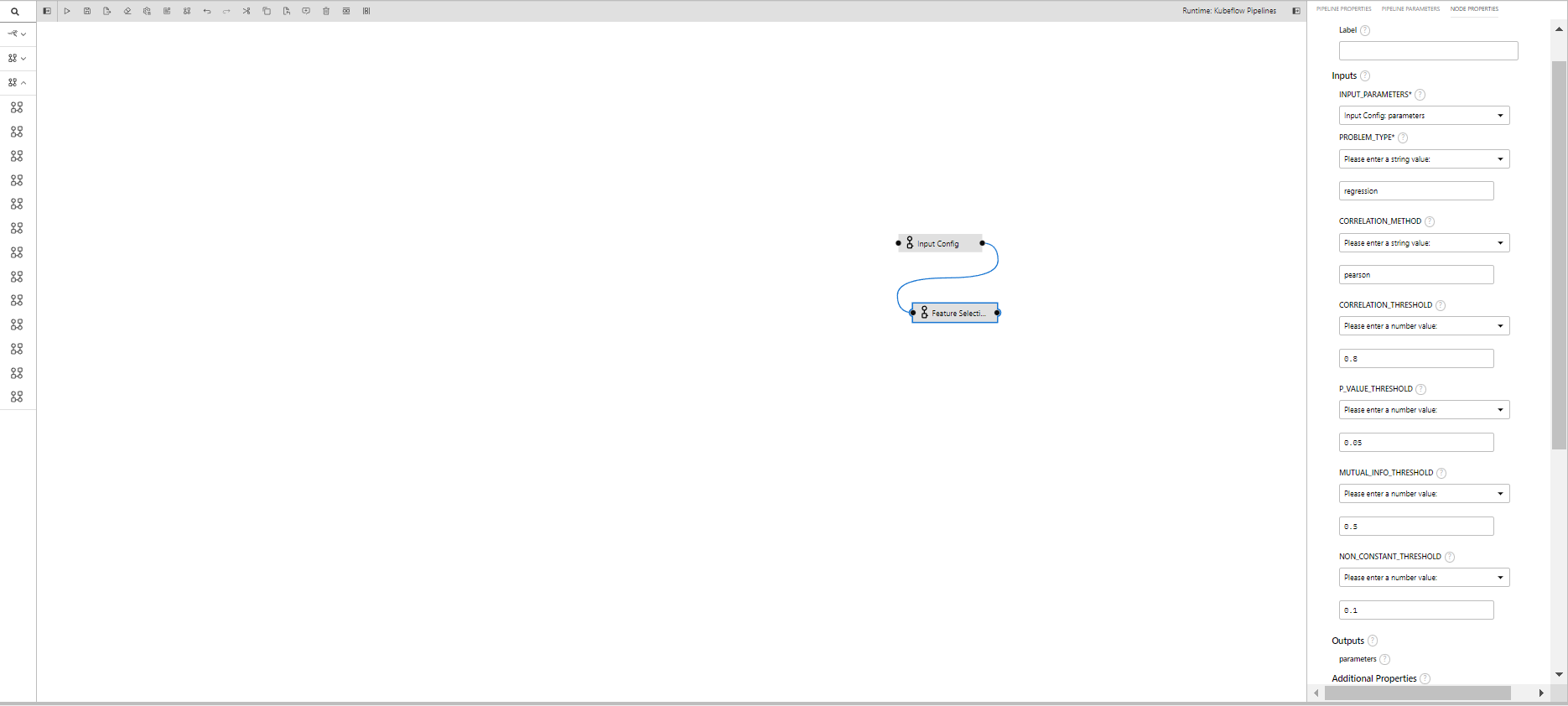
Feature Selection(RFE)
This component performs feature selection by eliminating features recursively and leaving the best possible feature for your operation.
- INPUT_PARAMETERS: Take the input parameter configurations from the previous component
- PROBLEM_TYPE: Whether the dataset is for regression or classification
- NO_OF_FEATURES: Total number of features to select
- STEP: Number of features to remove at each iteration
- VERBOSE: Controls verbosity of output
Feature Selection
This component performs feature selection by multiple factors and thresholds combined.
- INPUT_PARAMETERS: Take the input parameter configurations from the previous component
- PROBLEM_TYPE: Whether the dataset is for regression or classification
- CORRELATION_METHOD: Correlation methods to use(pearson,spearman,kendall)
- CORRELATION_THRESHOLD: Correlation threshold to filter columns
- P_VALUE_THRESHOLD: P-value threshold to filter column
- MUTUAL_INFO_THRESHOLD: Mutual information threshold to filter columns
- NON_CONSTANT_THRESHOLD: A minimum threshold value for a column to be non constant(Variance threshold of a numerical column)
Full Pipeline
All these components can be attached in the pipeline as per your requirements. However, a component may not run and your pipeline may fail if some undesirable inputs are given to the components.
To create a pipeline with custom components following steps need to be followed:
- Expand the palette by clicking on it.
- Drag and drop the Input Config component to the editor(This has to be the first component of any pipeline).
- Right click on the component and click on open properties
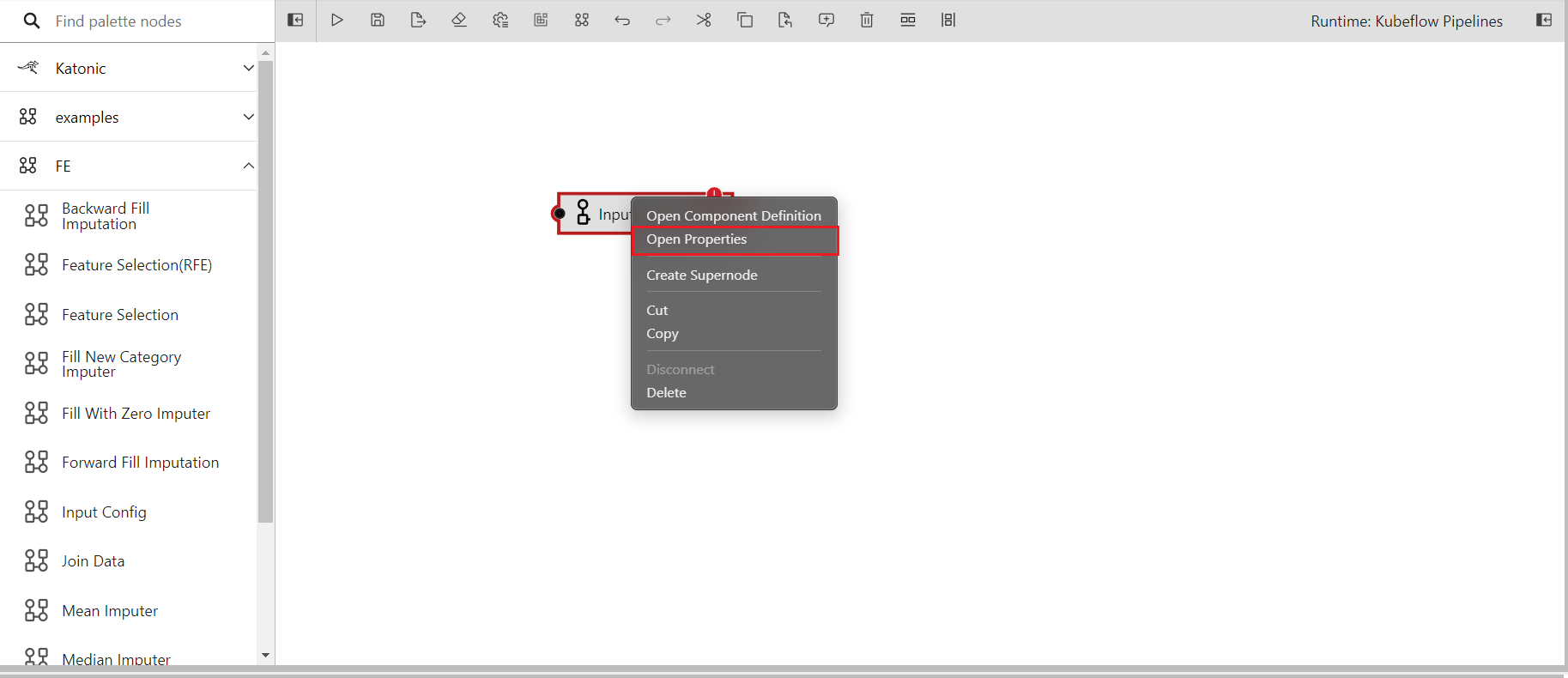
- You will see a new panel on the right side of the editor and different input boxed under node properties
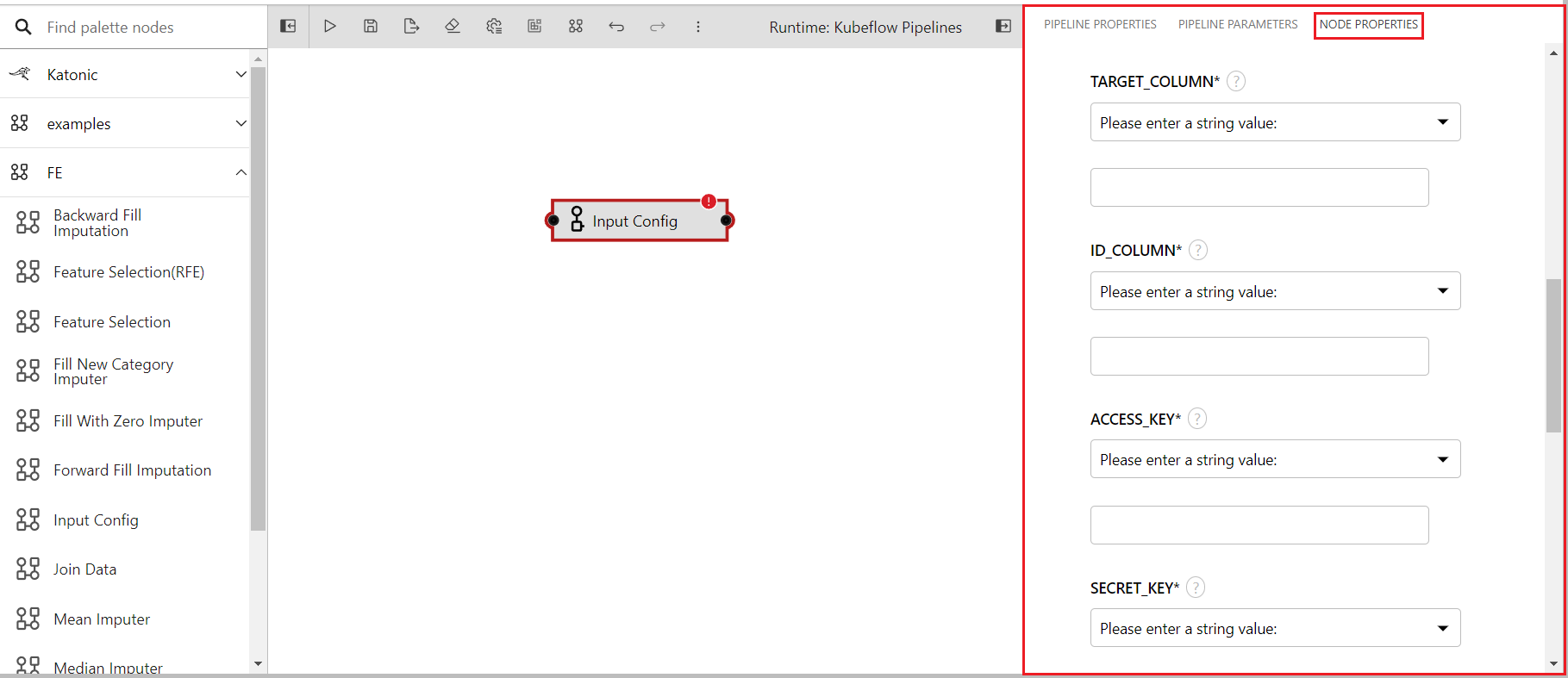
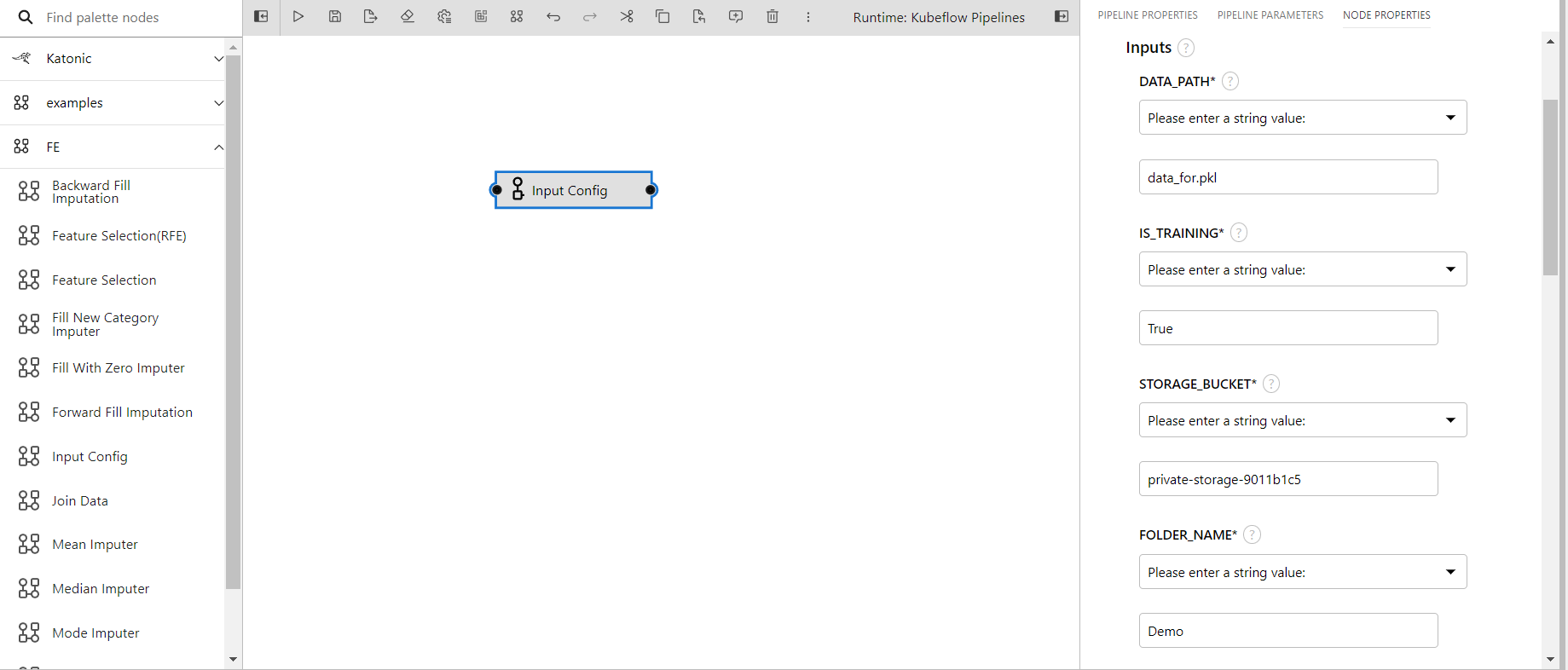
- Fill the input boxes with the input required.
- Here i have given data_for.pkl in DATA_PATH
- IS_TRAINING is True
- Given my private bucket name as the file resides inside the private bucket(The name can be found inside the file manager)
- FOLDER_NAME is given as Demo that will be created inside my private bucket with a timestamp
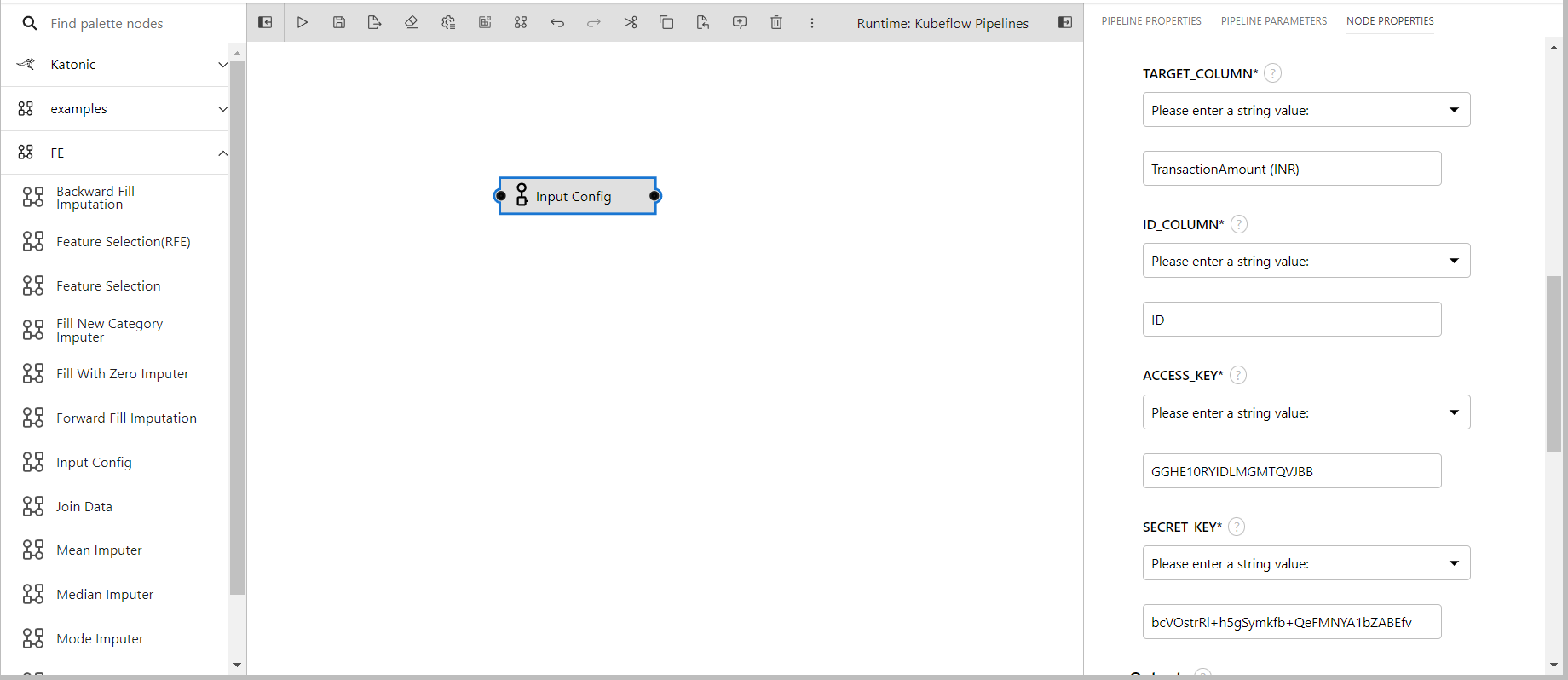
- TARGET_COLUMN is TransactionAmount (INR) for my dataset
- ID_COLUMN is ID in my dataset
- ACCESS_KEY is given GGHE10RYIDLMGMTQVJBB
- SECRET_KEY is bcVOstrRl+h5gSymkfb+QeFMNYA1bZABEfv Access key and secret key can be generated from the file manager tab.
- In the next step i'm dragging mean imputer in the pipeline editor
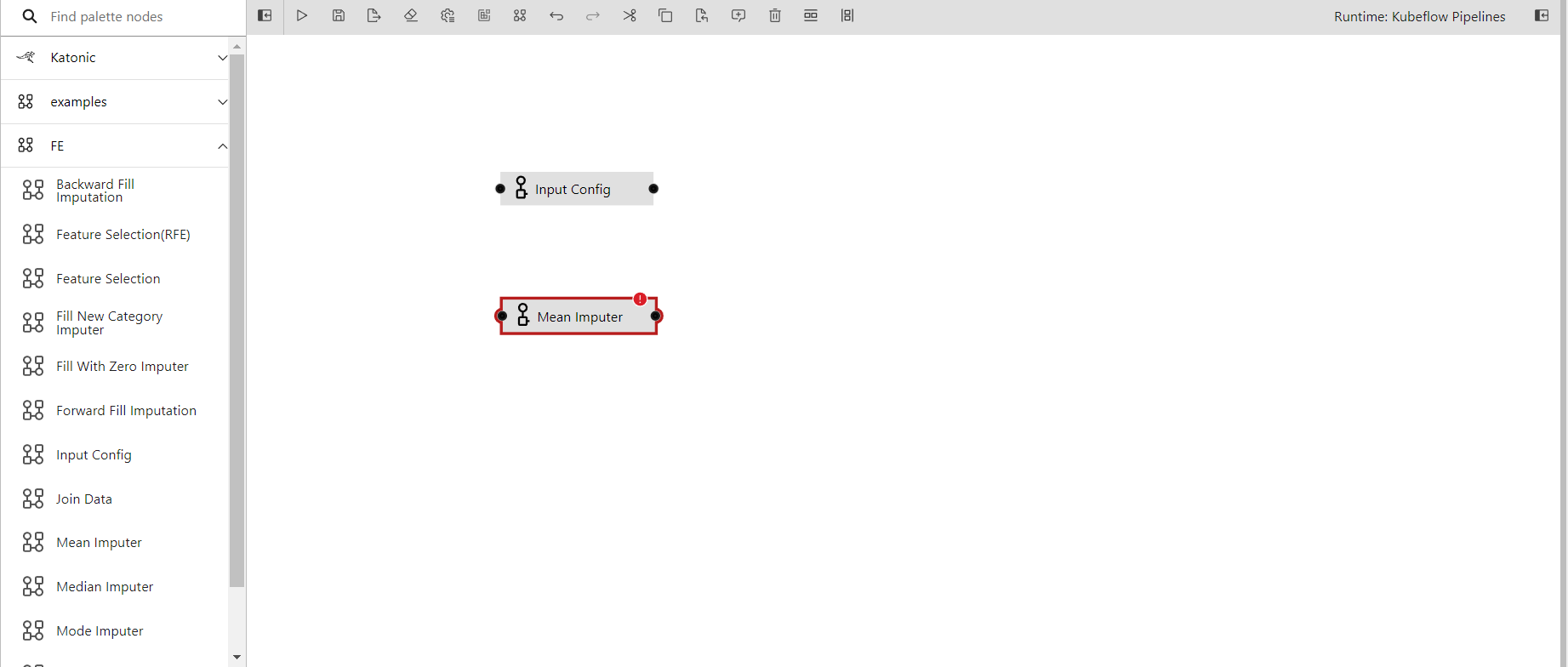
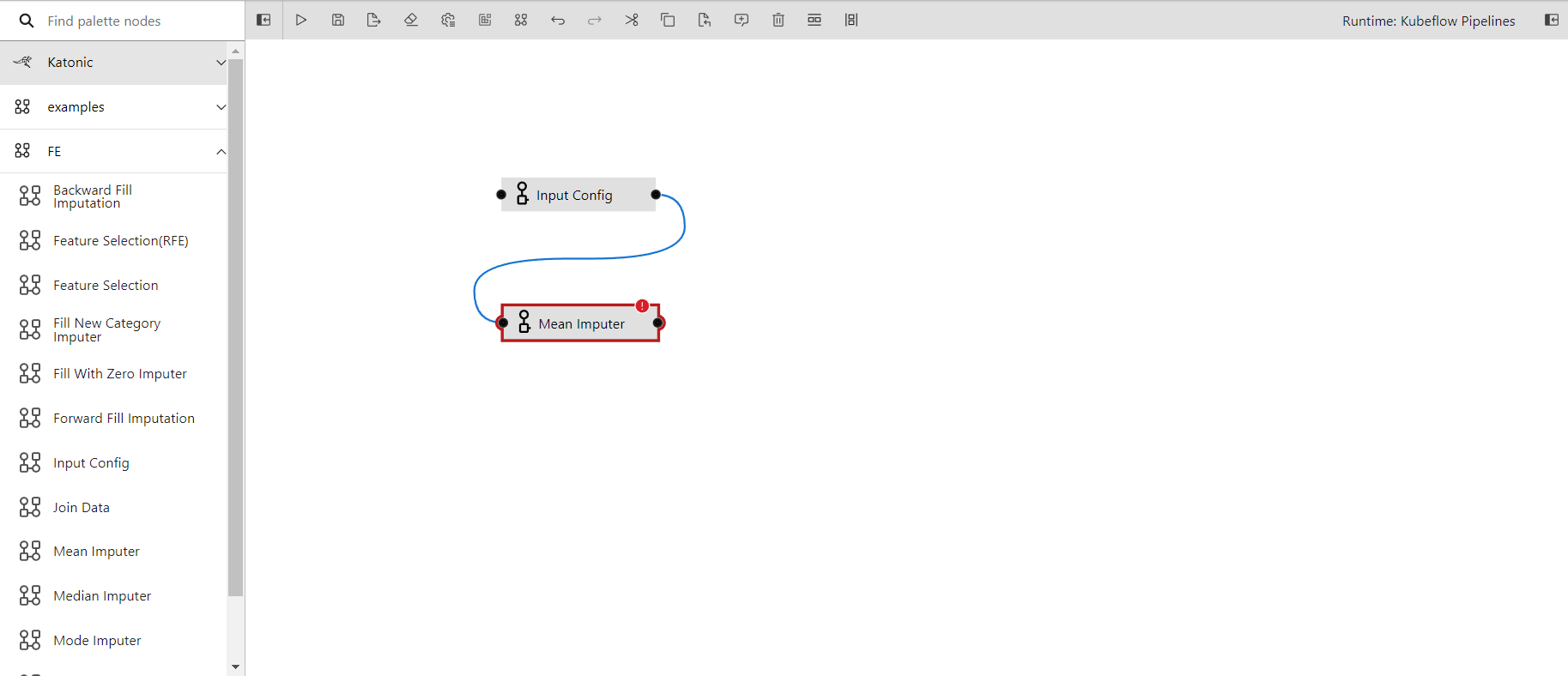
- Connecting the output port of the input config to the input port of the mean imputer
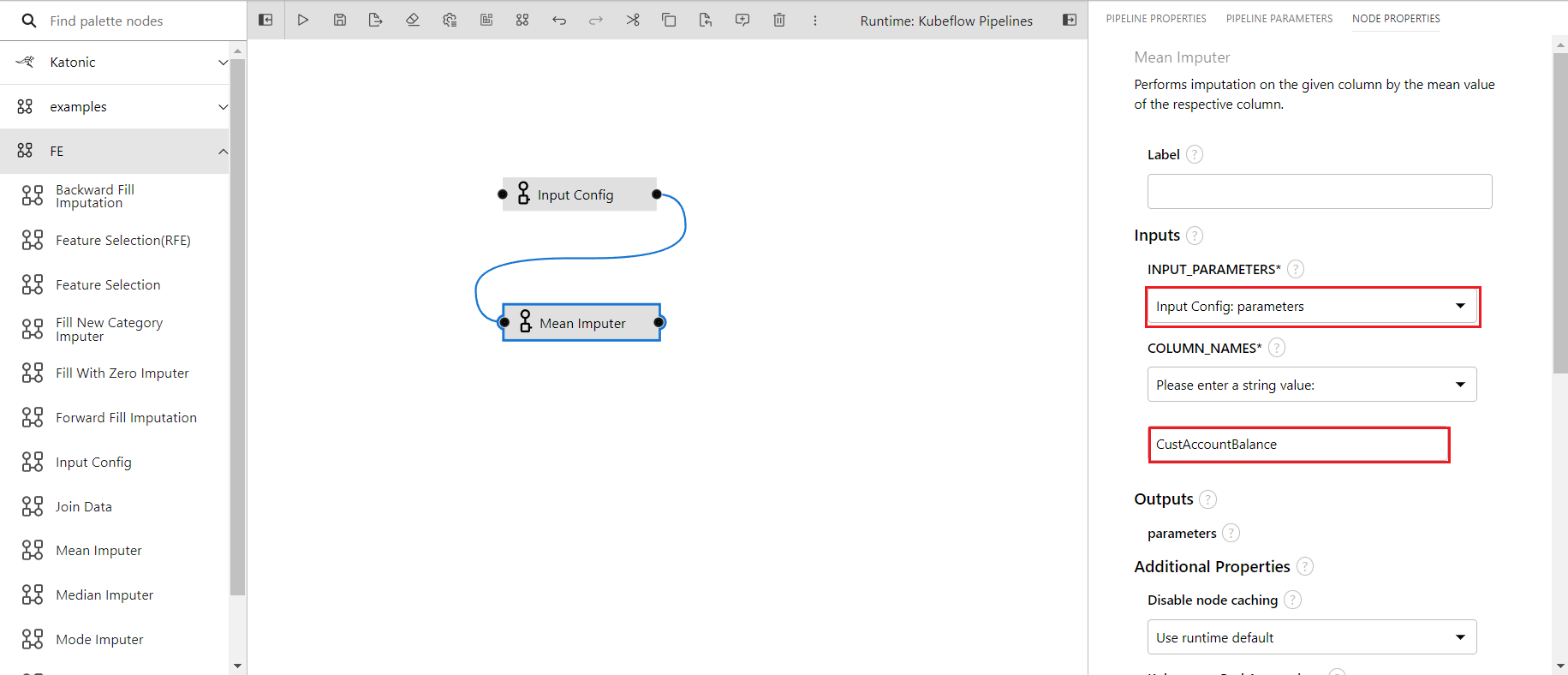
- In the properties of mean imputer providing inputs
- The input parameters is taken from the input config as it is it's previous/parent component
- Columns name is given as
CustAccountBalanceas i want to perform mean imputation on this column
- Dragged mode imputer in the editor
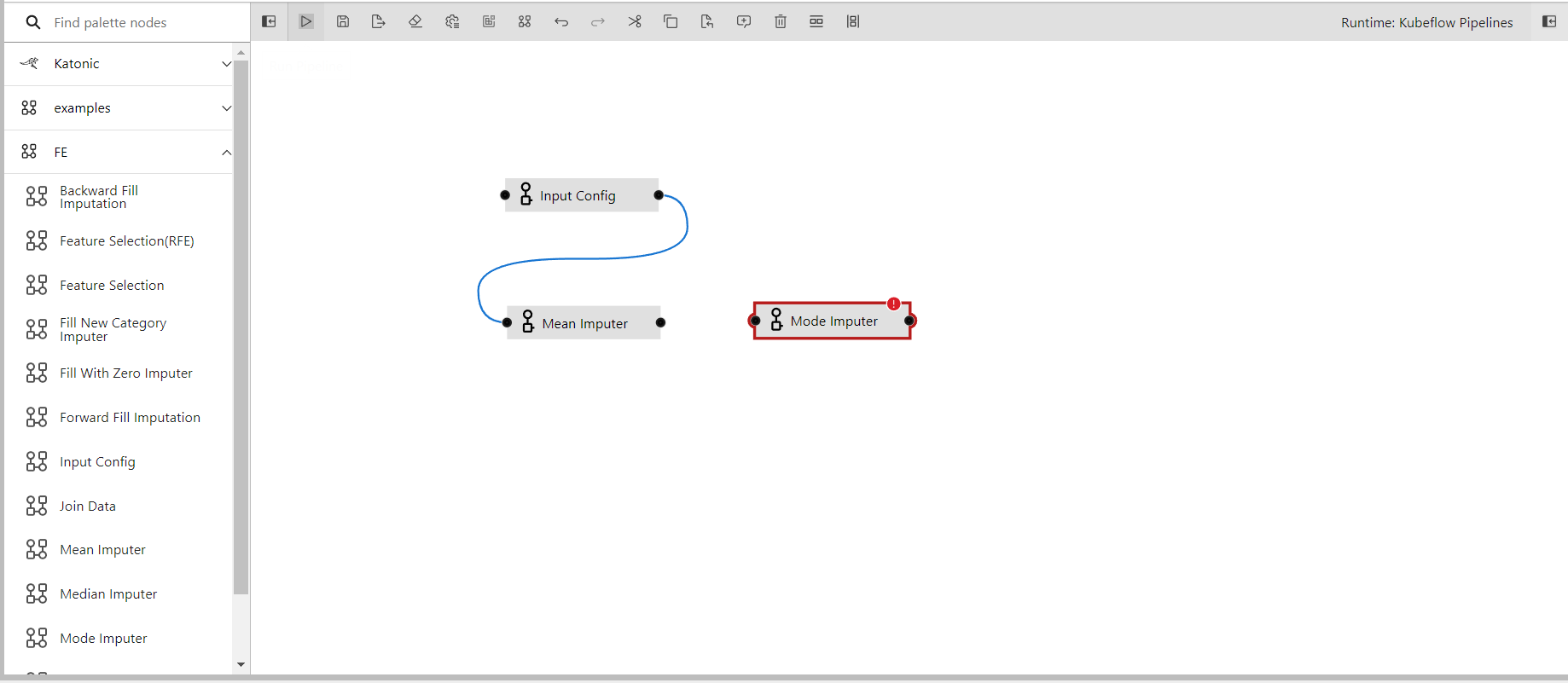
- Connecting the output port of the input config to the input port of the mode imputer
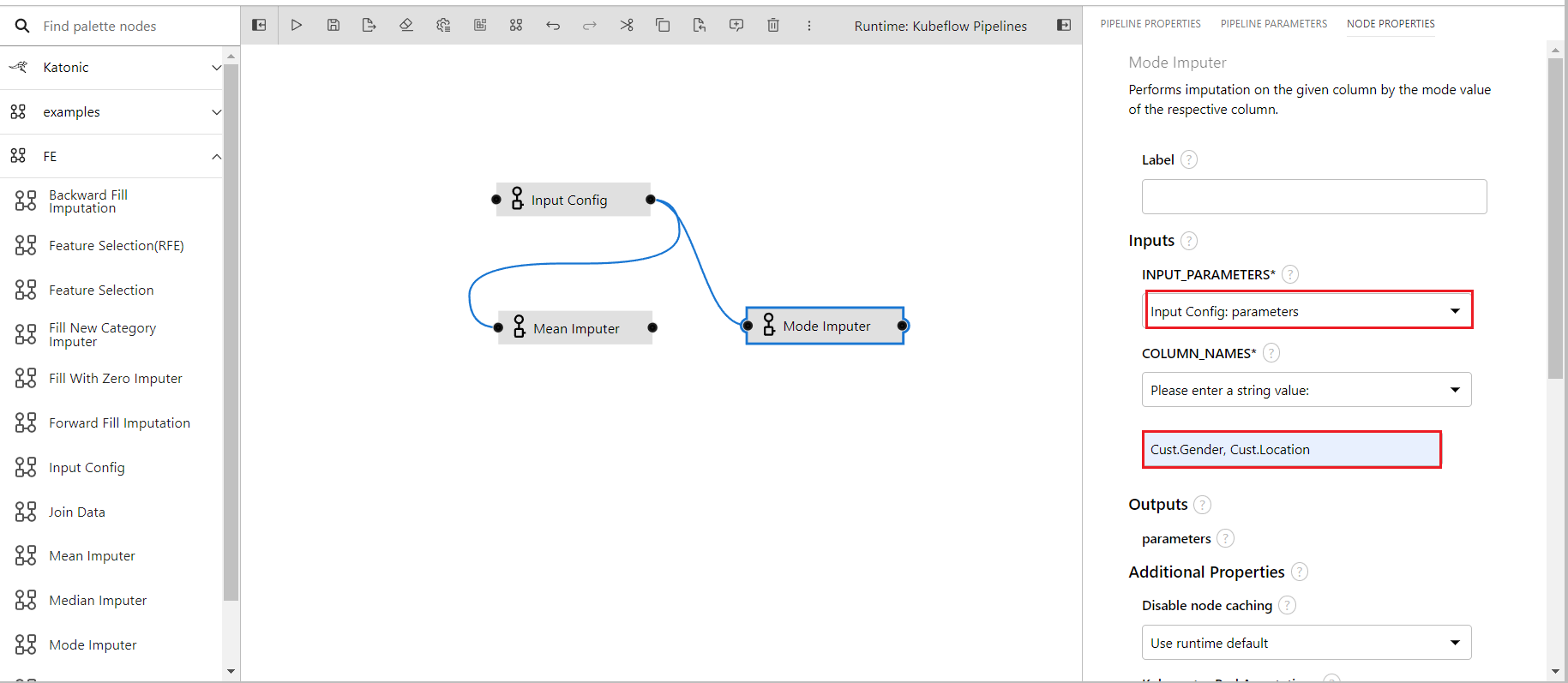
- In the properties of mode imputer providing inputs
- The input parameters is taken from the input config as it is it's previous/parent component
- Columns name is given two inputs this time
Cust.GenderandCust.Location
- Dragging the join data component to the editor, since the mean and the mode imputer ran parallelly so both the component outputs need to be joined using this component.
- The output port of the mean imputer and mode imputer is connected with the join data's input port
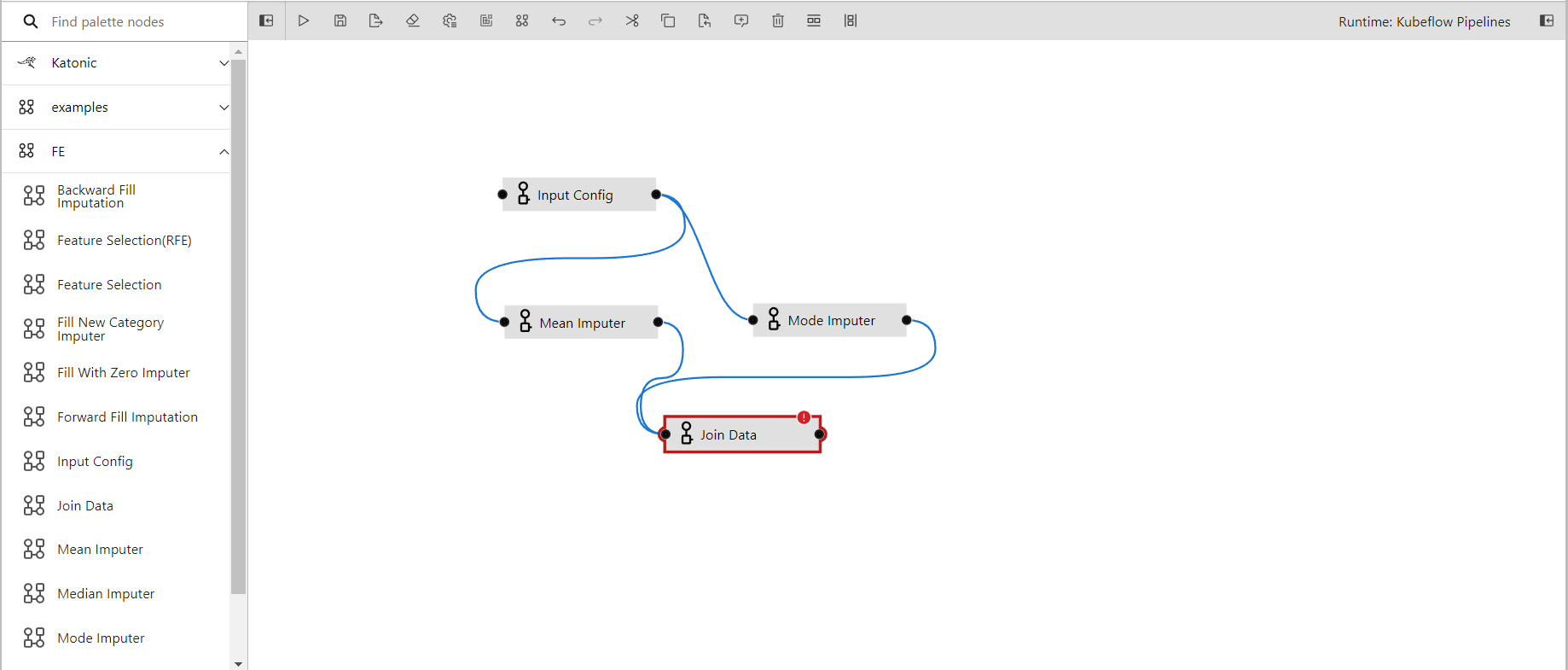
- In the properties of join data
- Input Parameters1 has input from the mean imputer
- Input Parameters2 has input from mode imputer
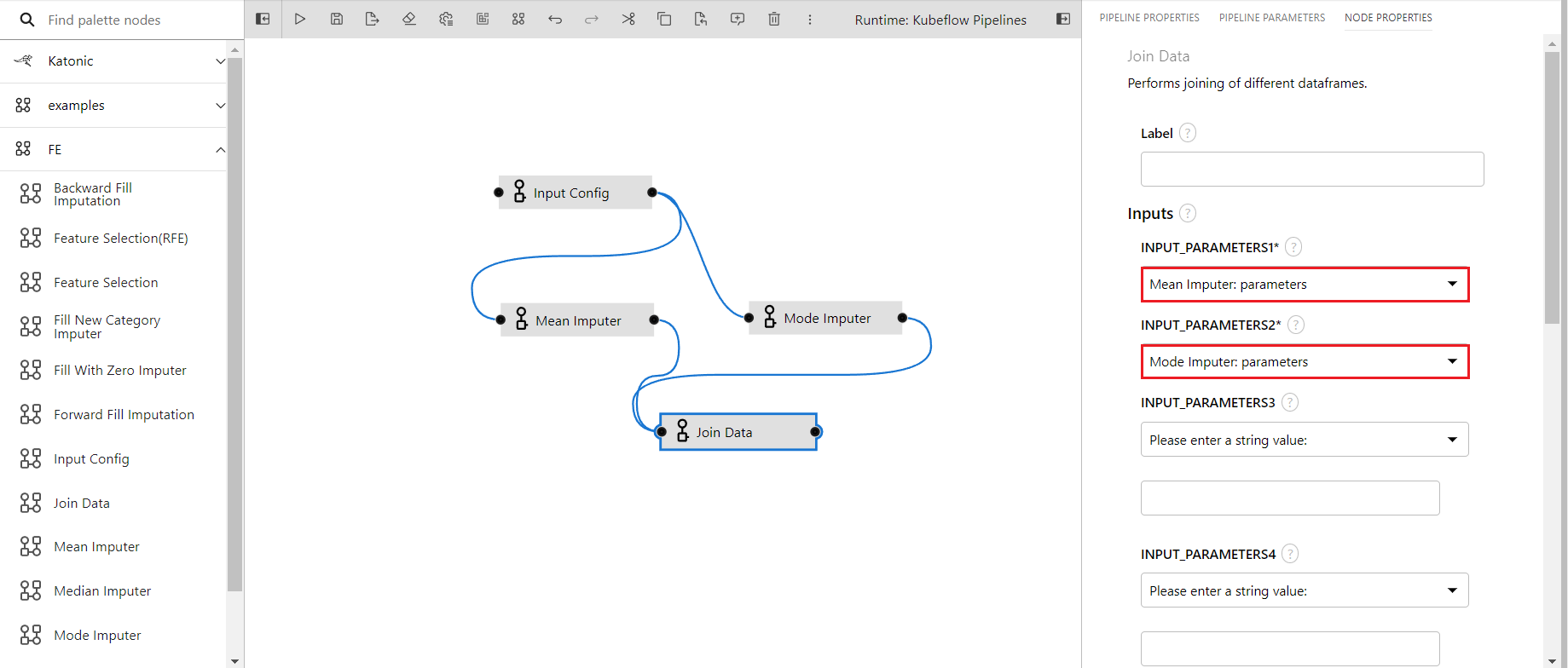
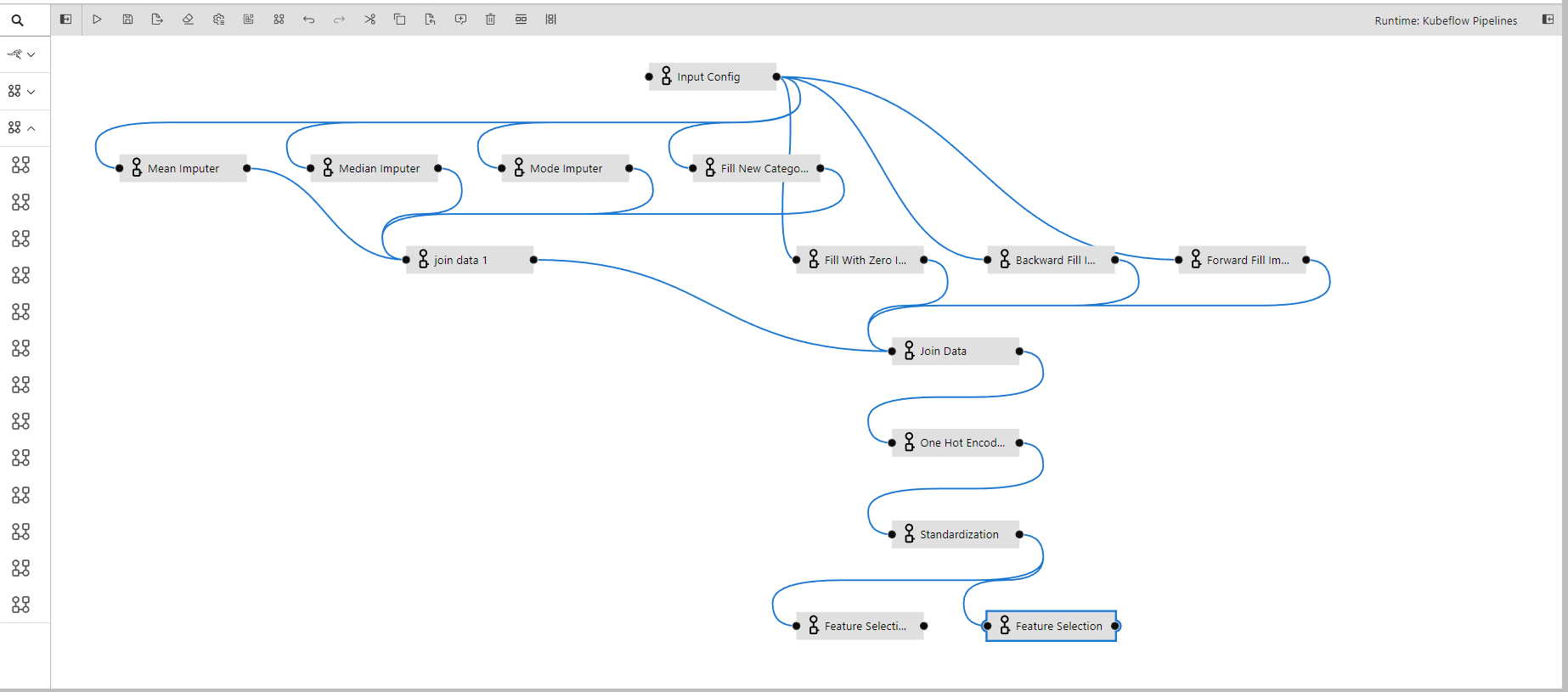
An example of the pipeline can be found here
As you keep proceed to build your pipeline then at the end your entire pipeline may look like this: